
目录
一、下载ollama并拉取大语言模型
二、安装Open WebUI及docker
三、通过python编写前后端代码
四、运行
链接: https://pan.baidu.com/s/1e4Y45CwlzUjrja9Tjpw7pw 提取码: hrnb
server.js和app.js的网盘链接
要是有不知道的或者哪里有问题报错建议直接问问通义千问,关于代码的问题他是真猛!!!!
一、下载ollama并拉取大语言模型
1.ollama官方地址:https://ollama.com/
2.Download键下载后打开
3.Install安装即可。安装后桌面右下角会出现ollama运行图标如图
4.在ollama官网找到对应要拉取的大预言模型名称,官方地址:https://ollama.com/search,我们选取的大语言模型为qwen2-7b大小的模型,效果一般,建议如果硬件设备允许的情况下安装体量和算例较大的模型,这样之后进行模型学习及问答的效果也更加优异。
。
5.选择对应的大语言模型点击进入,注意选择左侧模型大小,后复制右侧代码
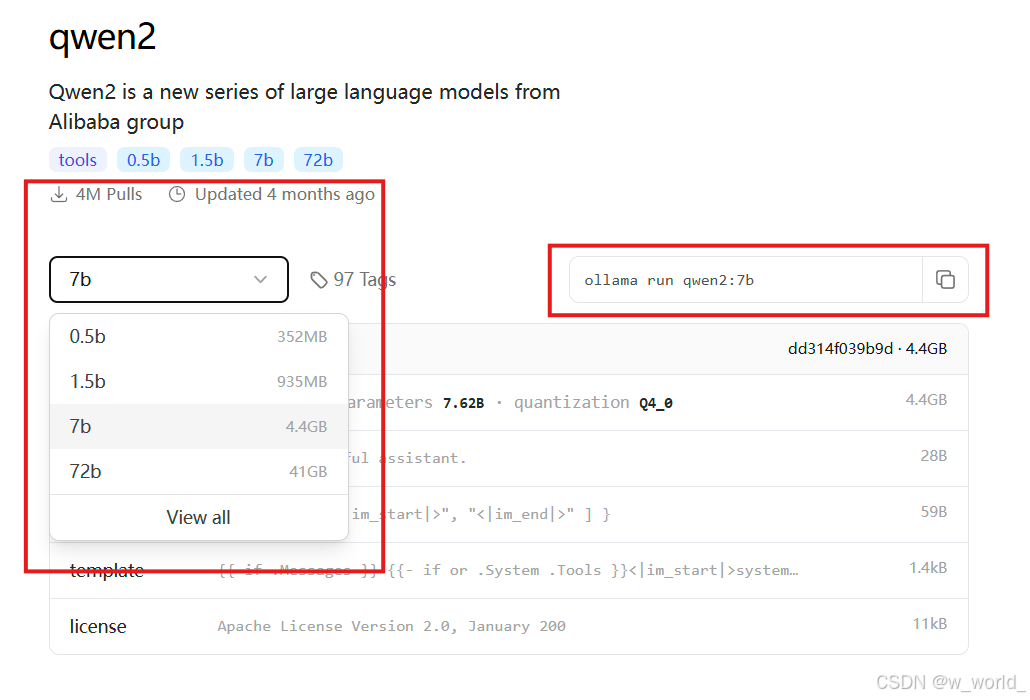
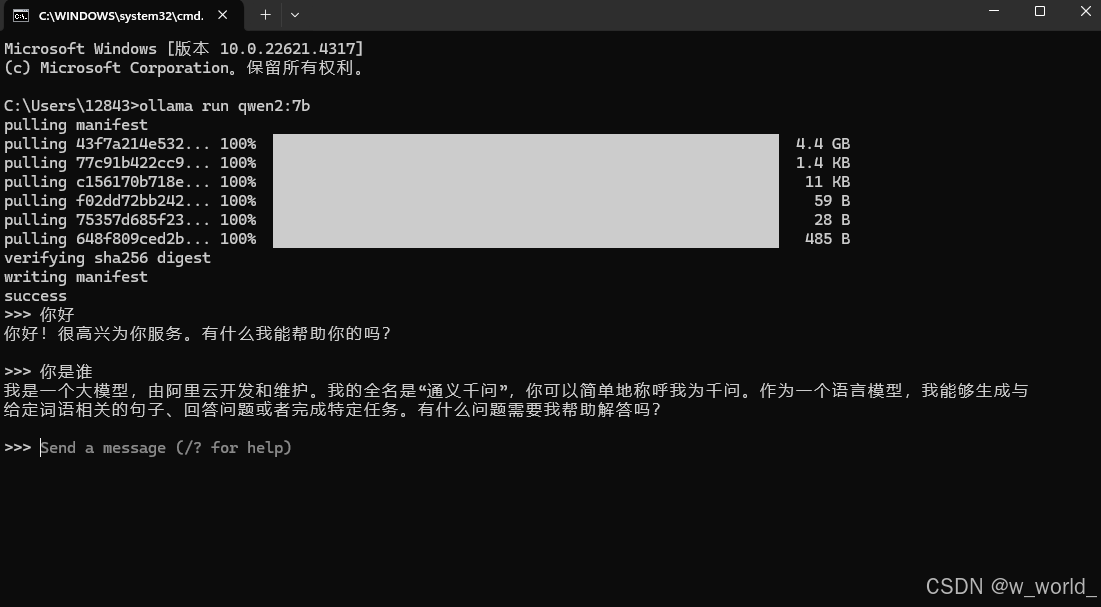
6.打开cmd命令符将刚刚复制的代码在cmd中运行,出现下图时表示模型拉取成功,可以进行问答检测
二、安装Open WebUI及docker
1.官方安装文档GitHub官网:https://github.com/open-webui/open-webui
2.通过python进行安装(确保python版本为3.11避免兼容问题):
(1)安装open-webui:pip install open-webui
(2)运行open-webui:open-webui serve
这将启动 Open WebUI 服务器,您可以在 http://localhost:8080
3.安装docker,官方网址:Docker: Accelerated Container Application Development,正常下载安装即可,文件夹中带有docker(4.37.1.0版本)安装包
因为我这里已经有一个版本的docker了,正常第一次安装时就直接install即可。
安装后保持docker是运行状态,为了防止之后创建大语言模型容器无法响应。
4.再次打开cmd命令符,选择GPU或CPU其中一个命令执行
安装带有捆绑 Ollama 支持的 Open WebUI
此安装方法使用将 Open WebUI 与 Ollama 捆绑在一起的单个容器映像,从而允许通过单个命令简化设置。根据您的硬件设置选择合适的命令:
(1)支持GPU,利用GPU进行运算:
docker run -d -p 3000:8080 --gpus=all -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama
(2)支持CPU,利用CPU进行运算:
docker run -d -p 3000:8080 -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama
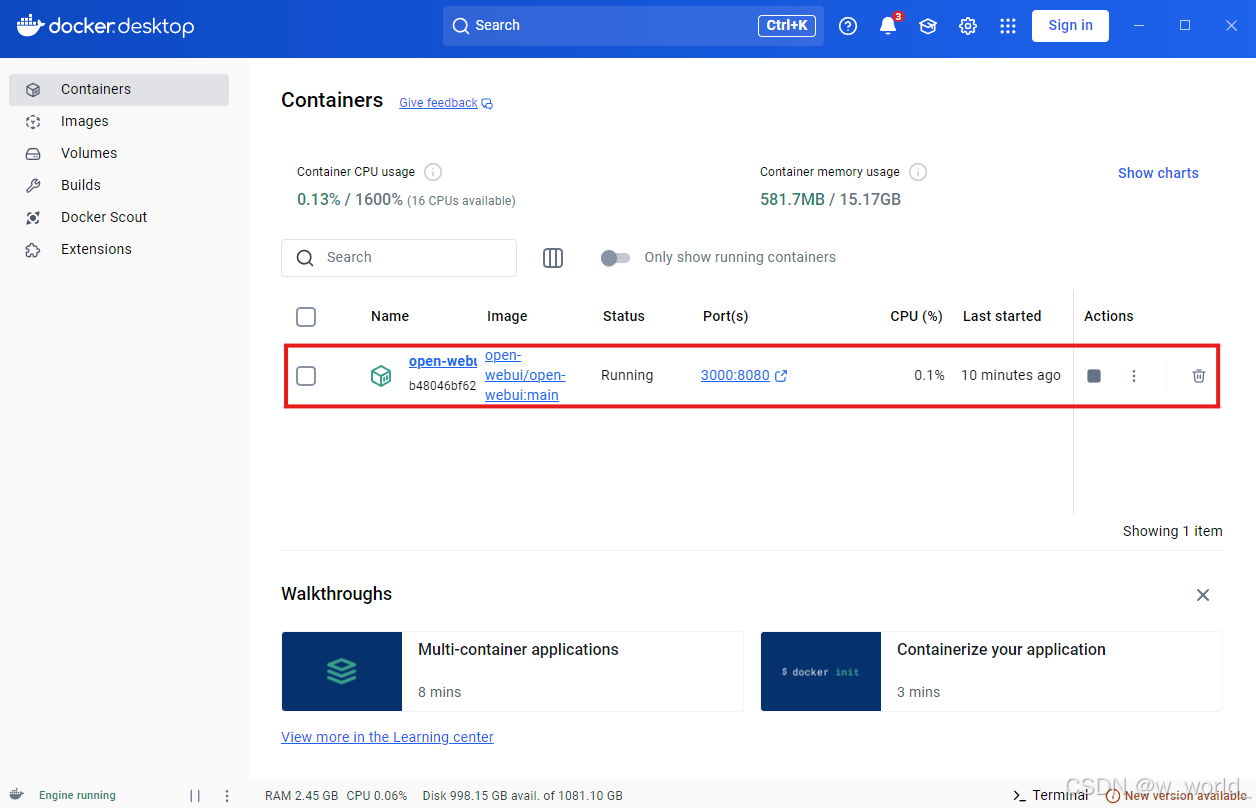
5.安装成功后docker应显示如下:
红框标出的容器即为你刚刚通过docker代码创建的模型容器,若没有红框内的内容则说明安装失败,建议重新打开docker或重启电脑。
三、通过python编写前后端代码
1.搭建环境
确保你已经安装了Node.js和npm。如果没有安装,可以从Node.js官网下载并安装最新版本,且本过程建议全程用cmd的管理员模式,防止一些过程因管理员权限问题报错。
(1)选择一个目标文件夹右键打开终端(如果报错见此win+R打开cmd后在慢慢跳转到指定文件夹内)
初始化一个新的Node.js项目:npm init -y
安装Express、Axios和Cors依赖:npm install express axios cors
(2)在该目录下创建一个前端目录
npx create-react-app frontend
cd frontend
npm start
将其中的APP.js文件换为本文件夹中的APP.js文件内容,需更改其中的32-34行代码的token、model、file_id参数,现在先不要动,还要再等一等。
(3)回到根目录下创建一个后端目录
创建一个server.js文件、chat_witch_model.py文件和documents.json文件
并将本文件夹内的文件将其替换,server.js第9行的IP改为你自己的ip地址,现在文件格式应该大致如下:
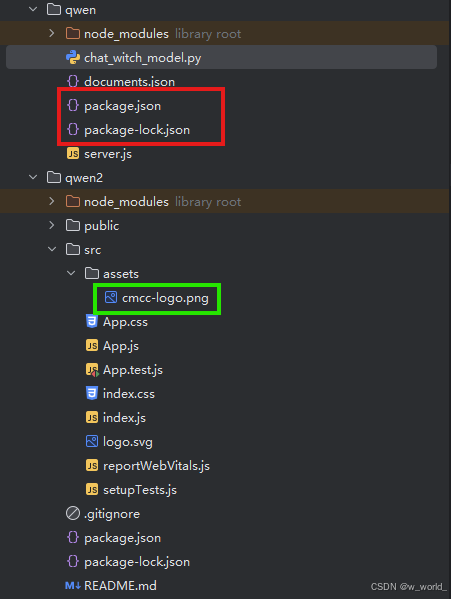
其中红色框内的文件有无皆可,绿色框文件是logo图标,请在目标目录下创建assets文件夹并将你想要的图片放入文件夹中。
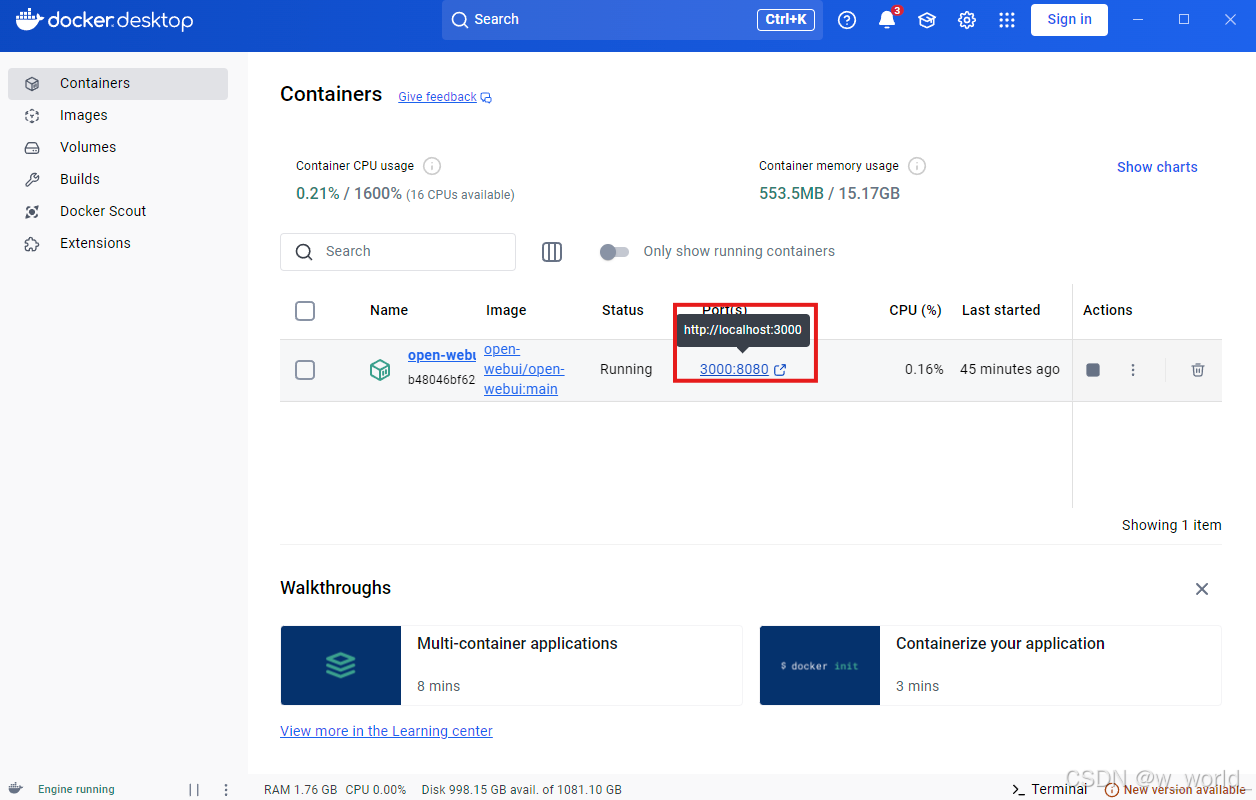
2.打开docker点击下图红框内的网址:
进入webui界面:
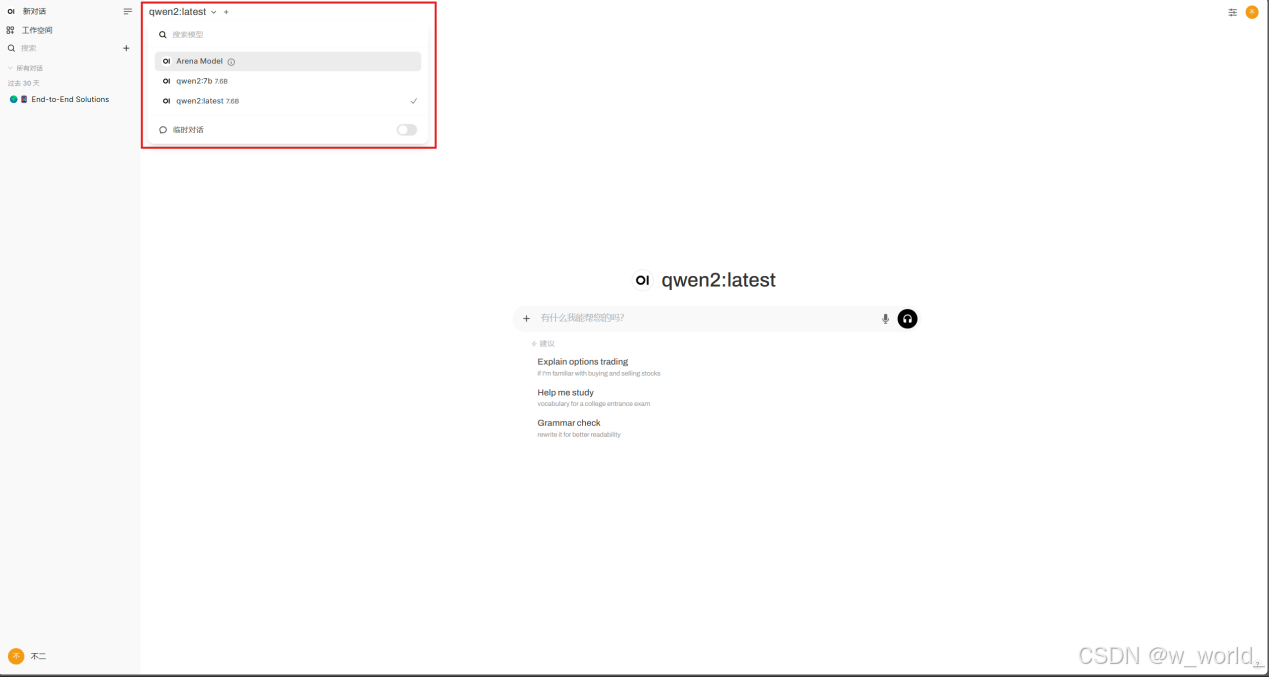
红框内是ollama拉取的模型,除Arena外应该还有一个你刚刚拉取的模型,我这里拉取的是qwen2模型,但需要复制的是全名(例:我这里就是qwen2:7b或qwen2:latest)
记住模型名称并在server.js(65行)和APP.js(33行)中找到模型名称更换。
点击左下角的用户名选择设置:
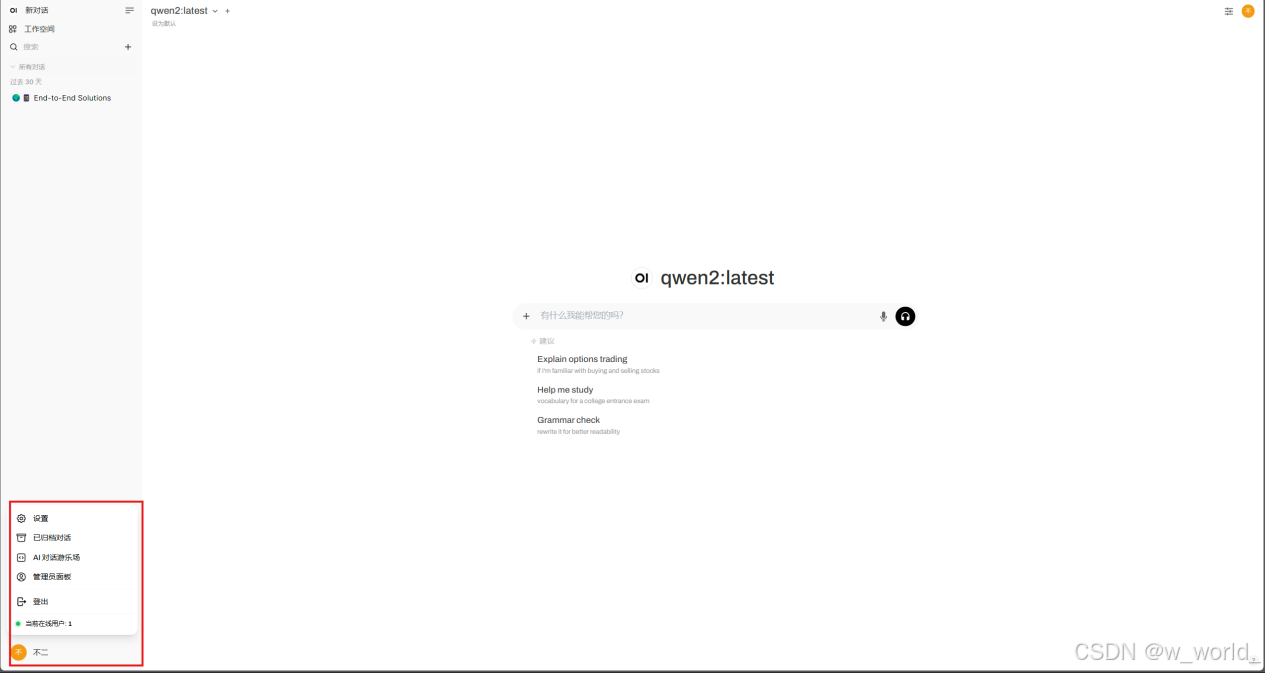
选择账号查看API密钥并复制:
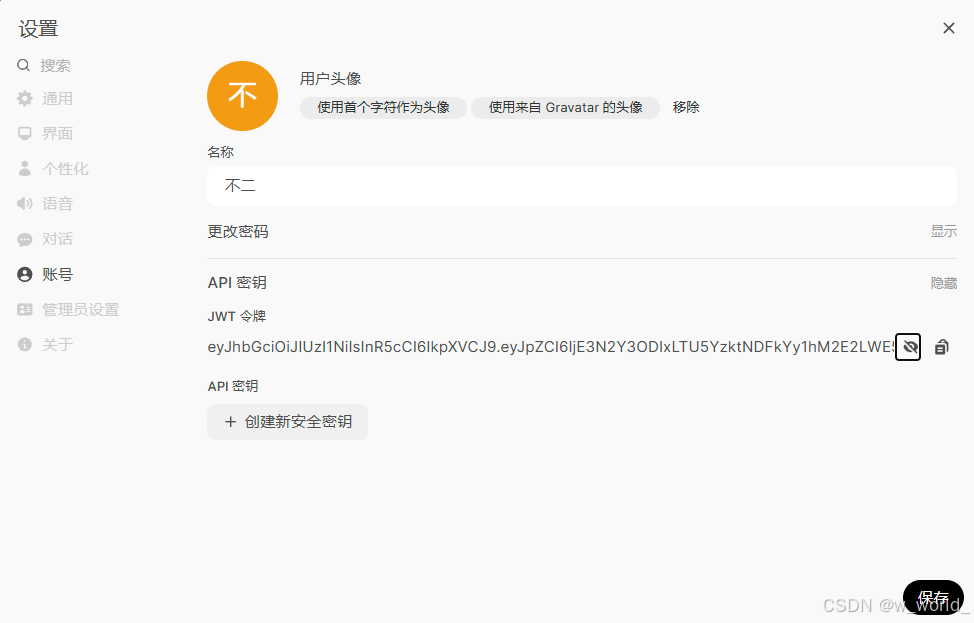
再回到server.js和APP.js中在刚刚更改的模型名称上面的token改为你对应的模型密钥。
3.文件上传和相关文件添加:
点击左上角的工作空间,点击上方的知识库模块,再点击右侧加号新建知识库。
可以在相应知识库中添加内容文件,本知识库上传文件支持txt、word、excel、pdf、ppt、html文件格式,其中以txt和word格式学习效果最佳。

这里需要找到你所创建的知识库id,我没有找到正当的搜索方法,我是通过上传两次同一文件后,他会报错,而我通过F12在浏览器后台找到了对应的知识库id号,如图:
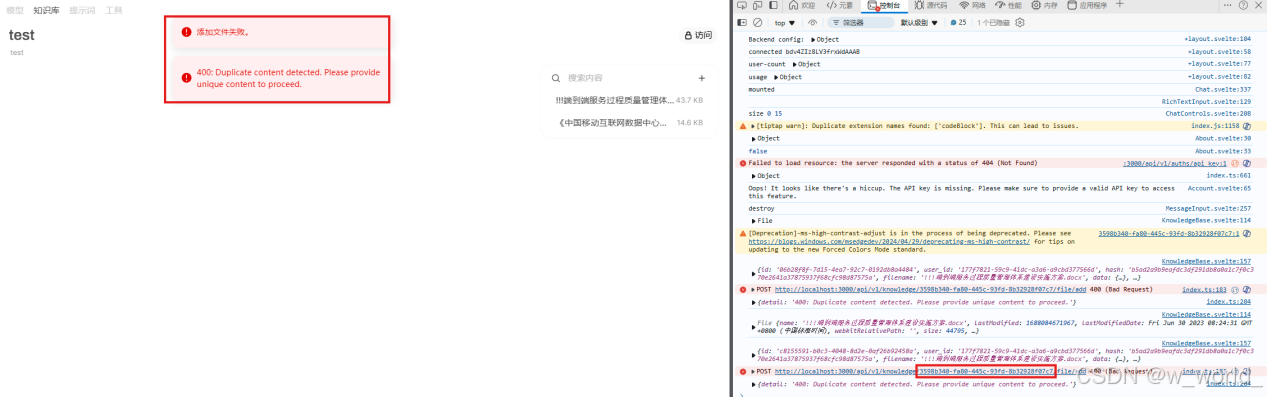
其中右侧红框中即为刚刚我所创建的知识库id号,复制,这个id号就是你需要更改的server.js(66行)和APP.js(34行)中的file_id参数。
至此我们工作已经基本完毕,通过更改了token、model、file_id及IP四个参数已经可以实现模型通过我们上传的文件进行问答。
相关文档的显示我无法通过调用模型的回答中返回的相关文件序号来显示出相关文档,所以我创建了一个documents.json文件将所有的文件都转化为txt格式的文件并编号,将其全部存放其中,且我通过自然语言理解和字符串相似度比对的方式,以关联性从高到低的方式将其排列。
documents.js文件也已经存放到本文件夹内。
四、运行
1.打开两个cmd命令符,分别进入到server.js和APP.js的根目录中运行代码(全程ollama和docker要保持启动状态):
(1)在有server.js的文件夹中运行:node server
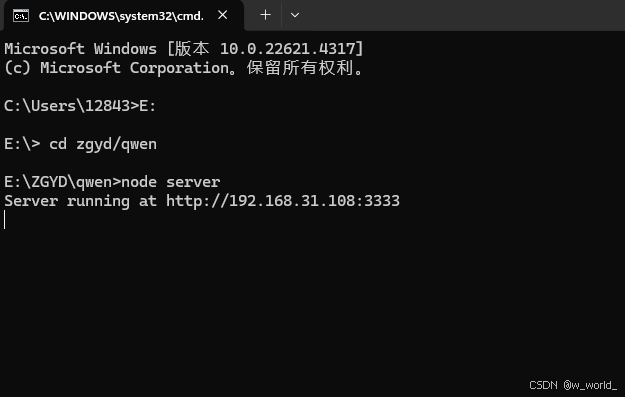
(2)在有app.js的文件夹中运行:npm start
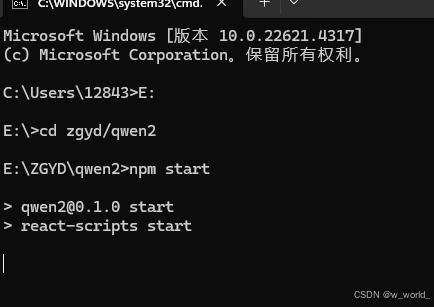
此步骤运行时可能会出现以下情况:
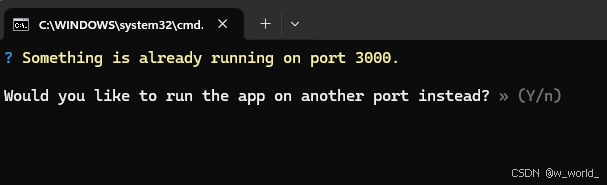
这种情况直接输入Y即可,他会自动跳变加一变为3001。
最终的结果应该如下:
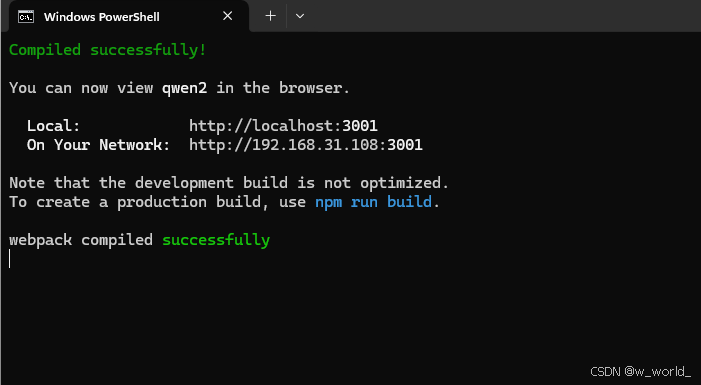
且同时会打开一个网址如图:
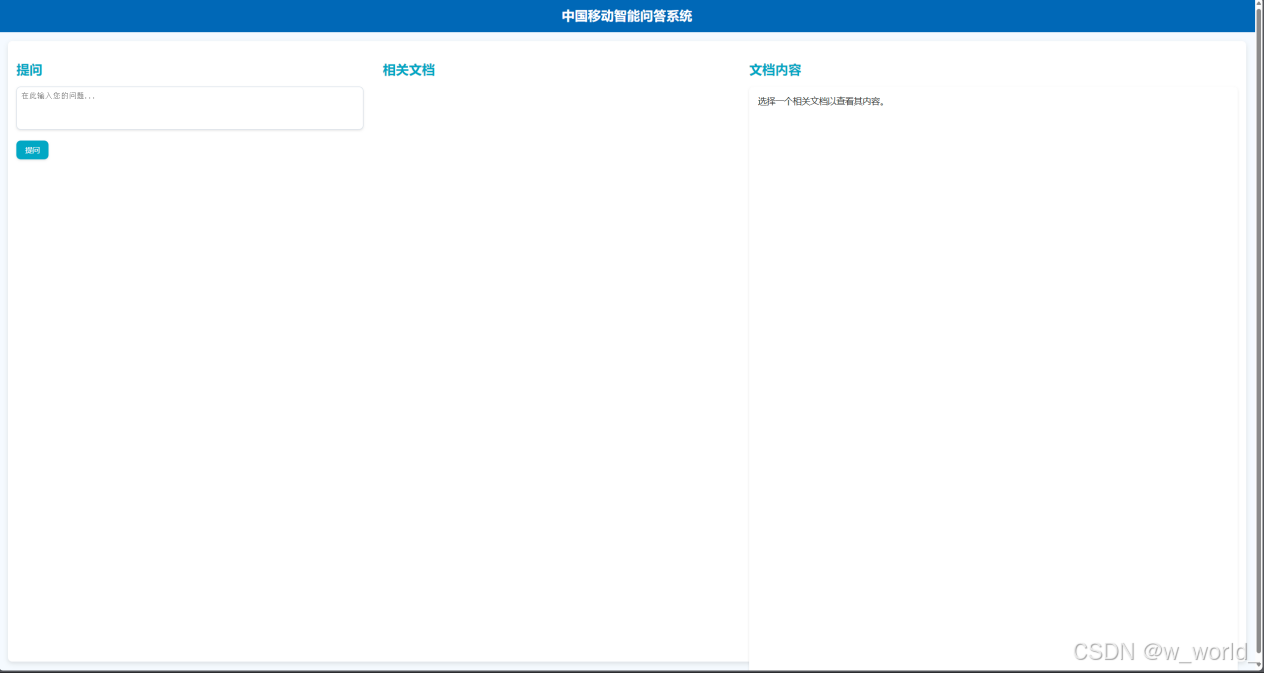
在此界面即可进行问答与相关文档的检索:
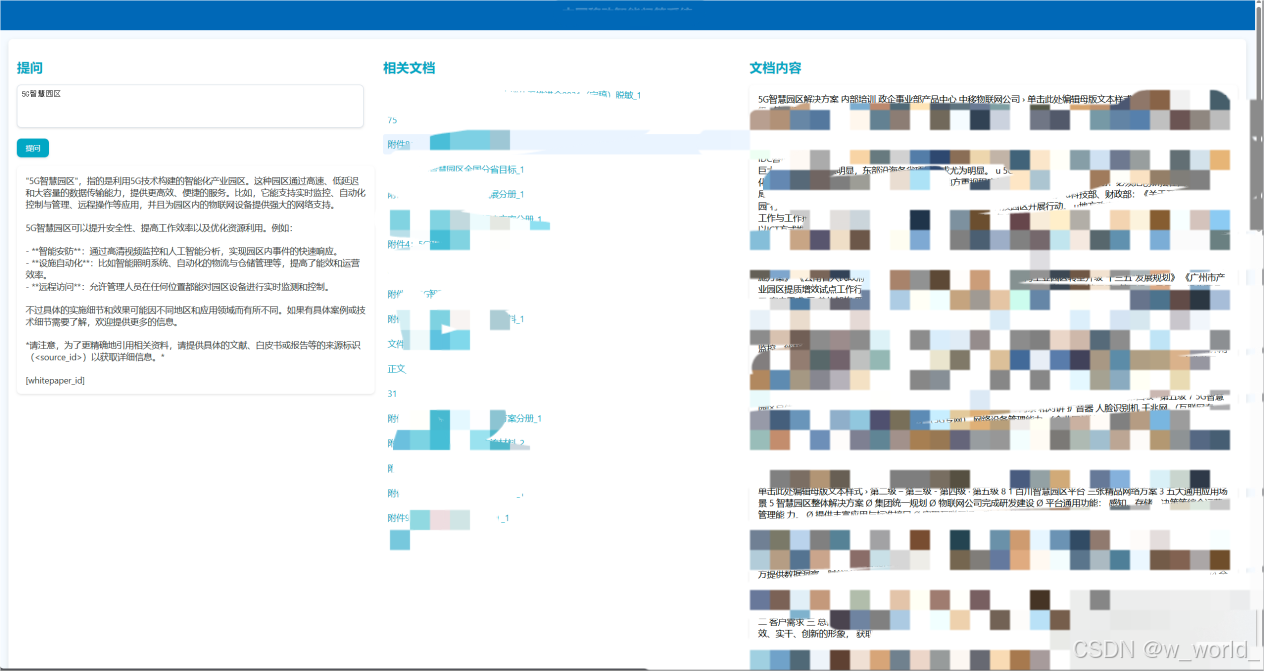
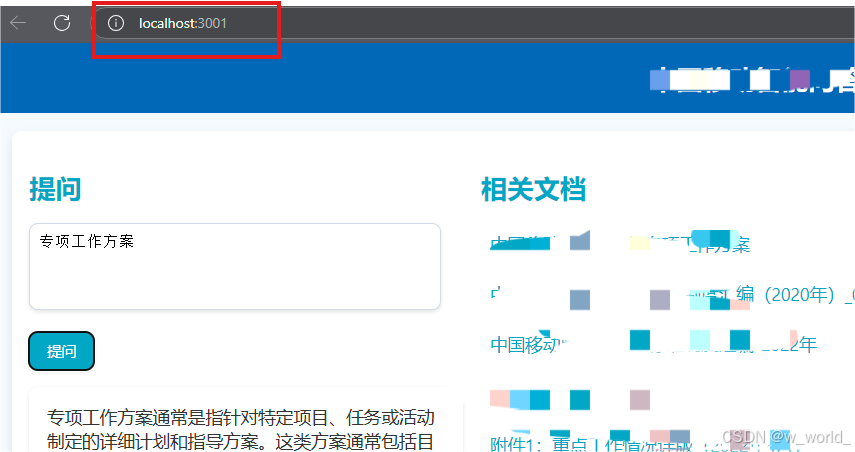
同时实现局域网内其他电脑通过设定的端口号访问:
本机电脑本地访问
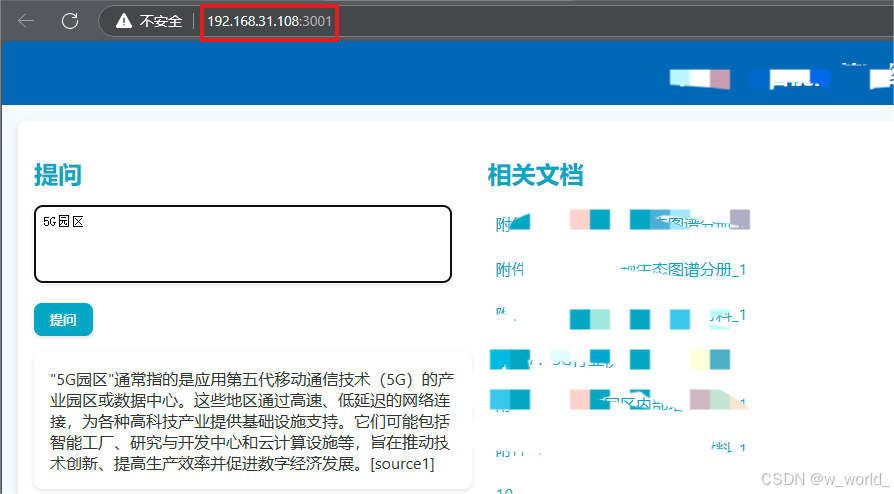
局域网内其他设备通过IP端口号访问
IP地址为你的IP地址后+:3001(例:192.168.31.108:3001)
至此实现全部功能。
最后如果再根据你想要实现的功能更改前端界面,大功告成!!!!

")

实现本地部署DeepSeek-R1-14B模型")