
大模型
使用win系统安装
使用sh脚本安装
使用docker安装
下载大模型
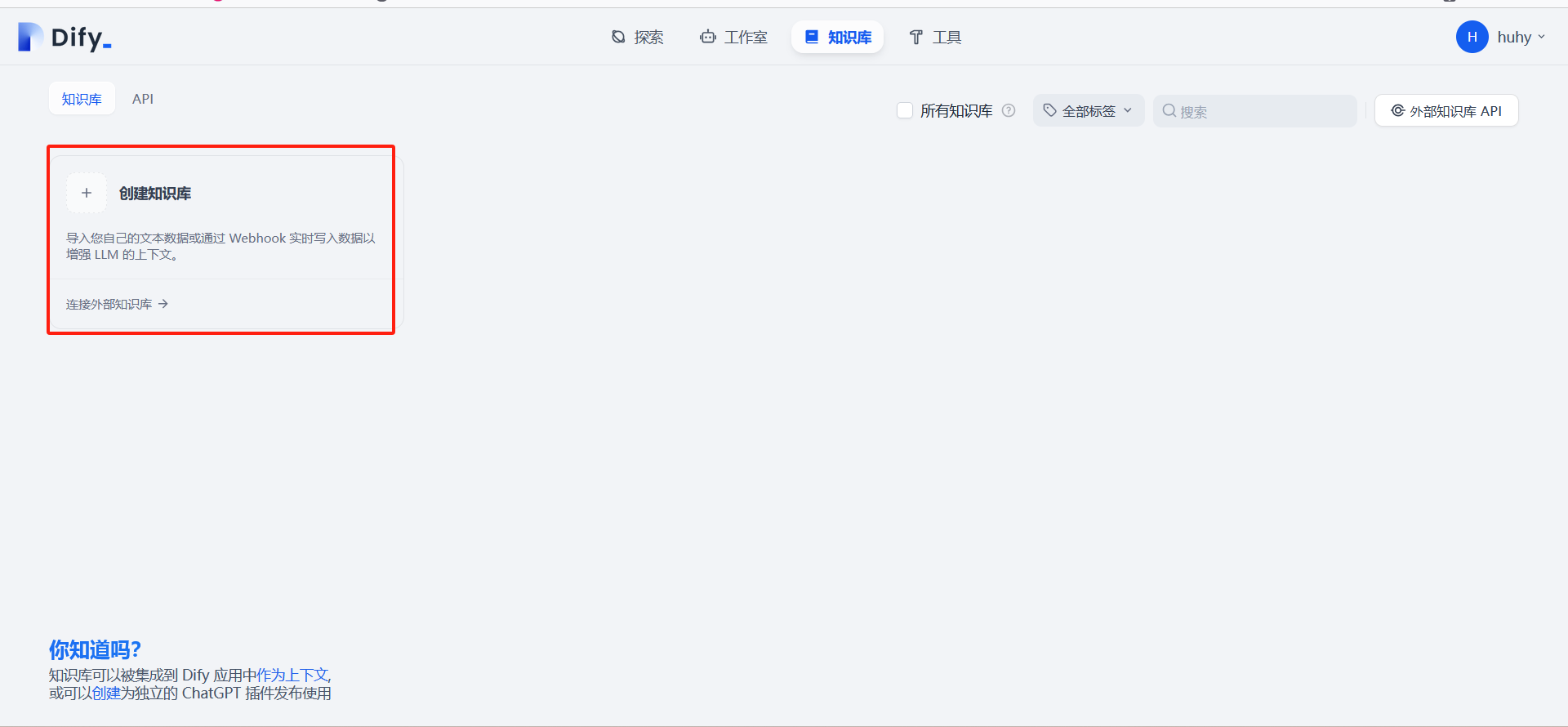
搭建WebUI工具和本地知识库
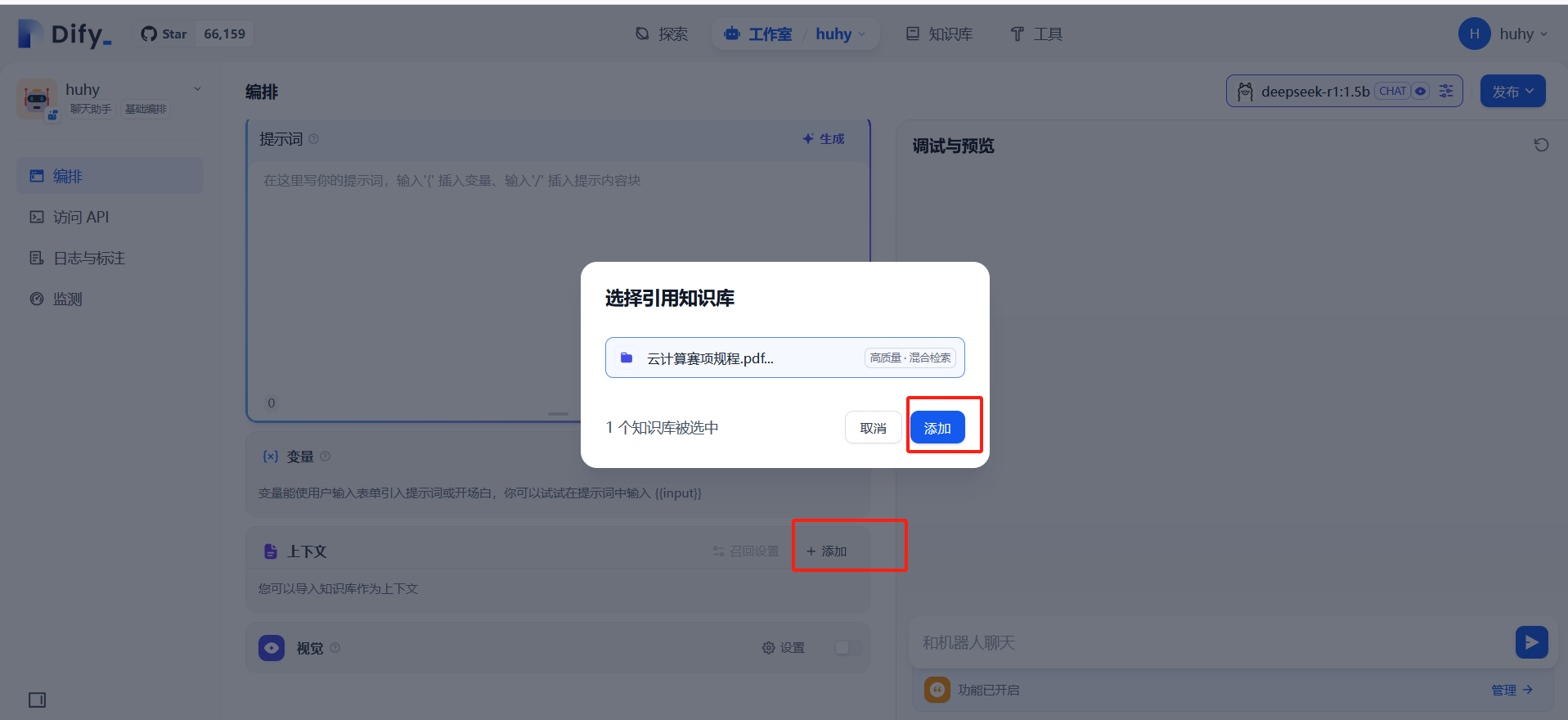
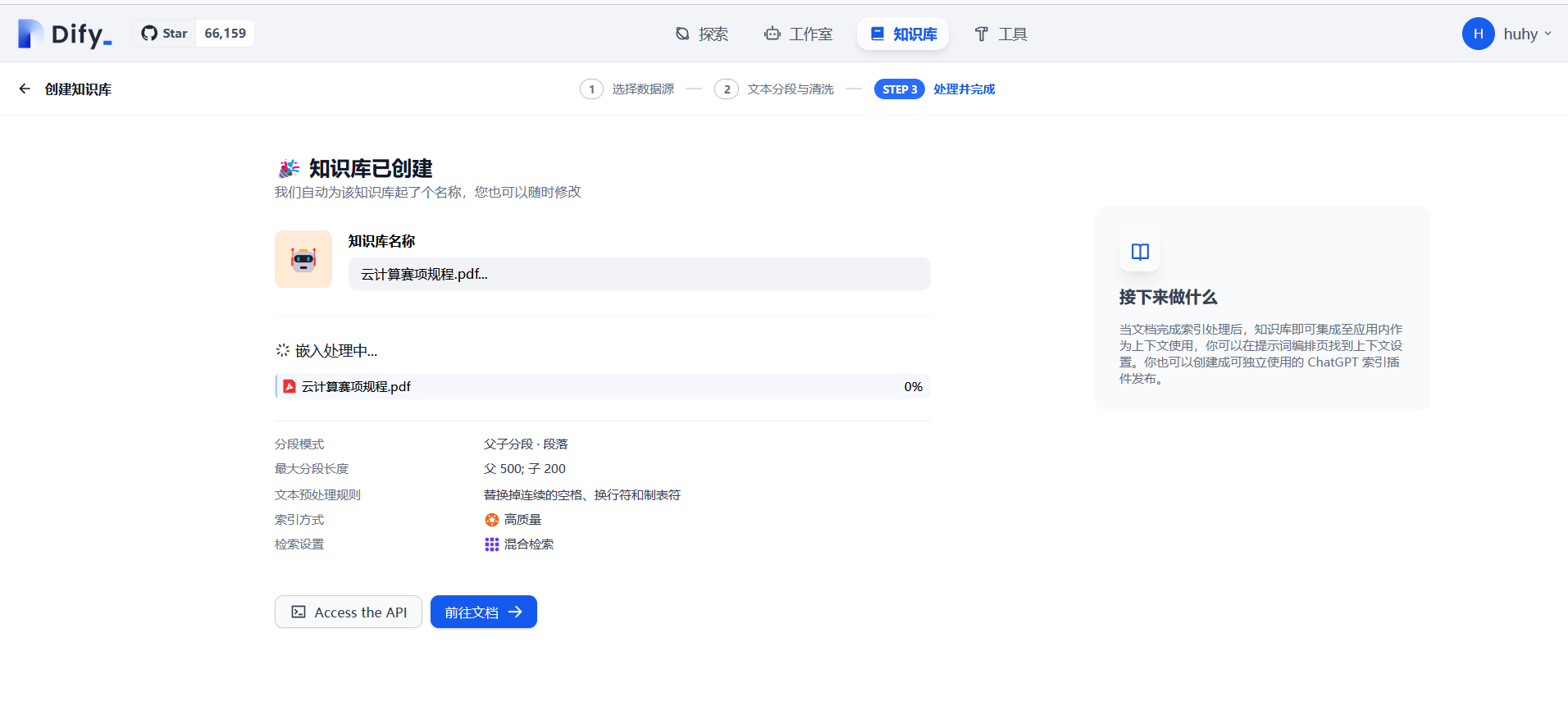
配置本地知识库
Docker安装MaxKb
配置本地知识库
Docker安装AnythingLLM
配置本地知识库
大模型(LLM,Large Language Model)指的是 参数量巨大、基于深度学习训练的人工智能模型,用于 自然语言处理(NLP) 任务,如文本生成、对话、翻译、代码补全等。它们通常由数十亿到万亿级别的参数组成,能够理解和生成类似人类的文本。
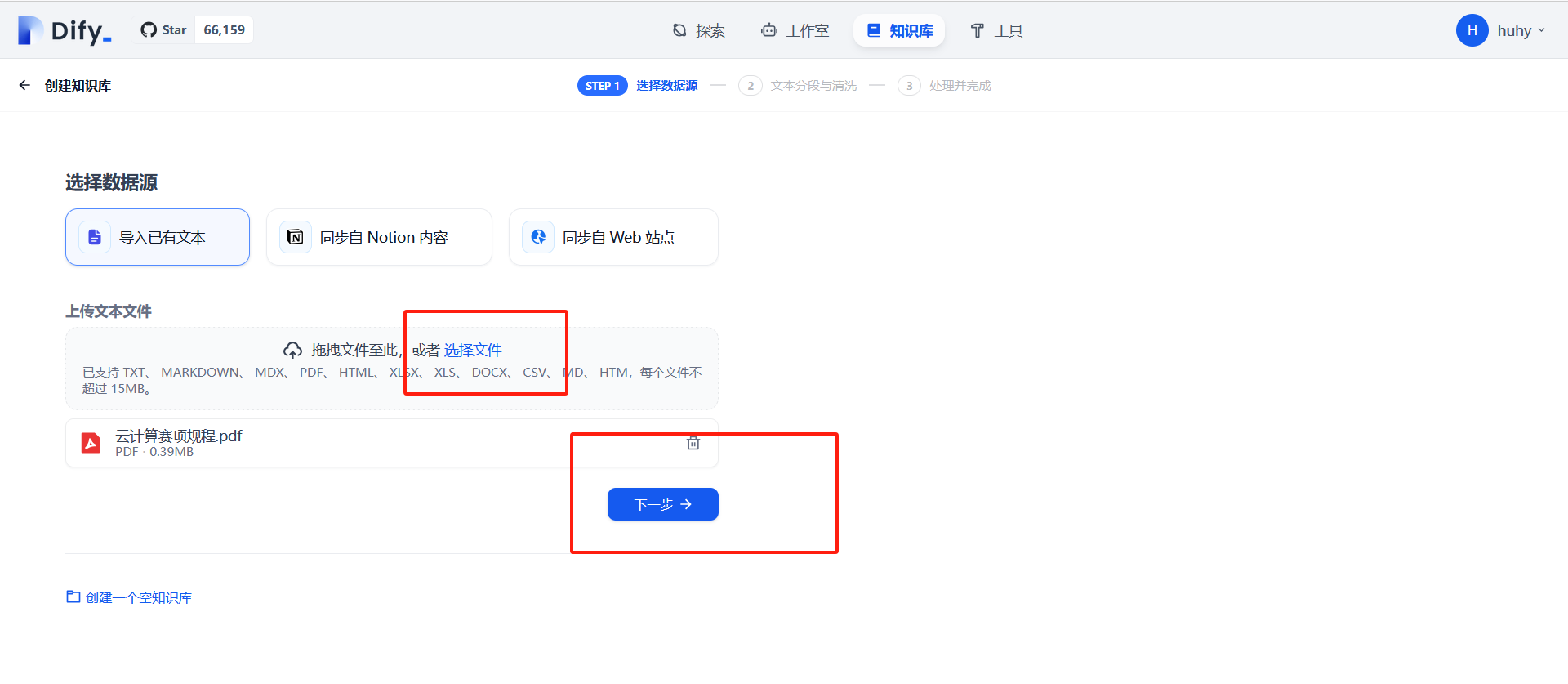
上传文件或目录即可
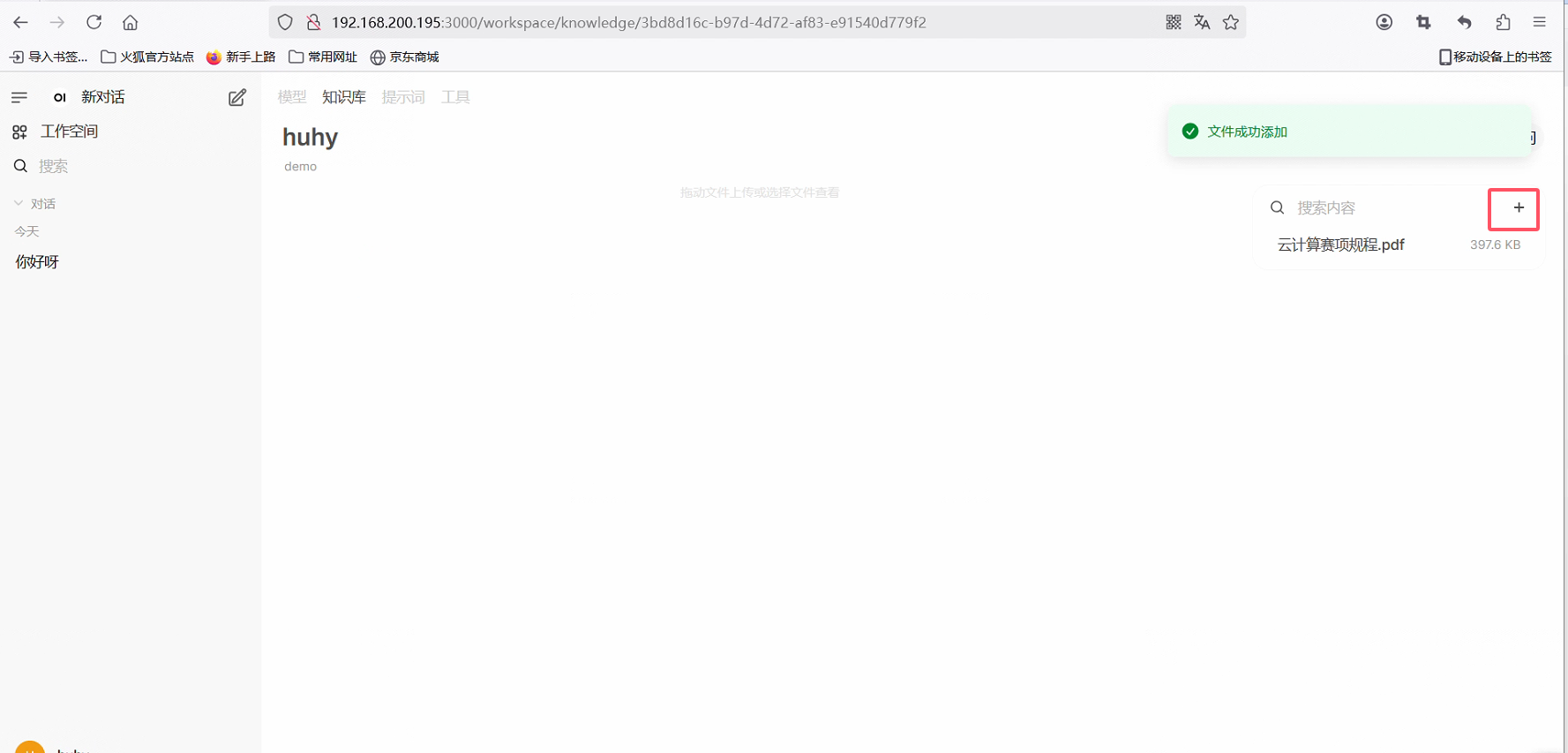
Docker安装AnythingLLM
GitHub官网
AnythingLLM是一个全栈应用程序,可以使用现成的商业大语言模型或流行的开源大语言模型,再结合向量数据库解决方案构建一个私有ChatGPT,不再受制于人:可以本地运行,也可以远程托管,并能够与提供的任何文档智能聊天。
给目录授权,不然容器创建后会自动退出
chmod -R 777 $HOME/anythingllm
界面访问:http://localhost:3001
创建工作区域
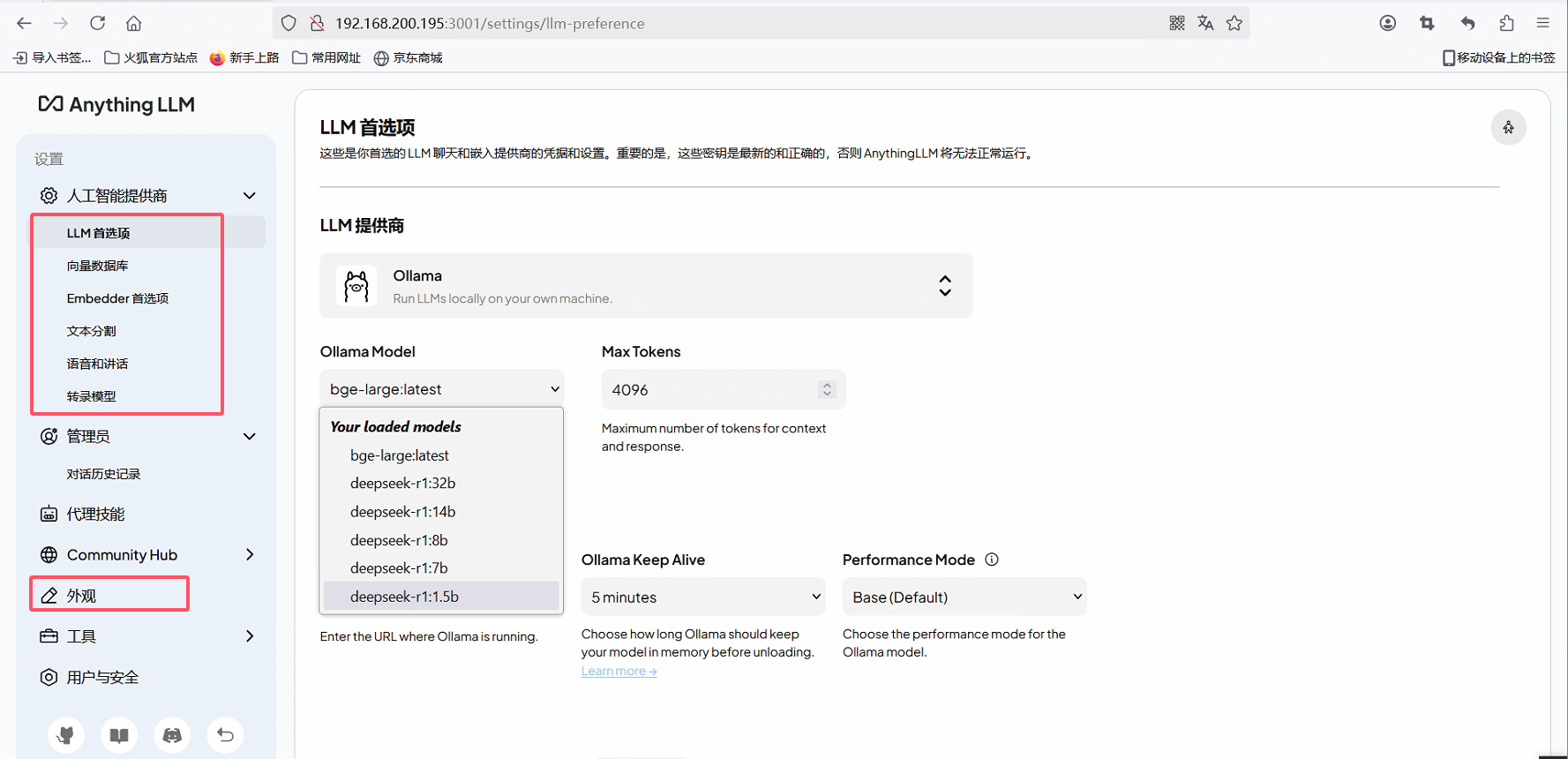
可以配置模型提供商信息,以及自定义外观界面等
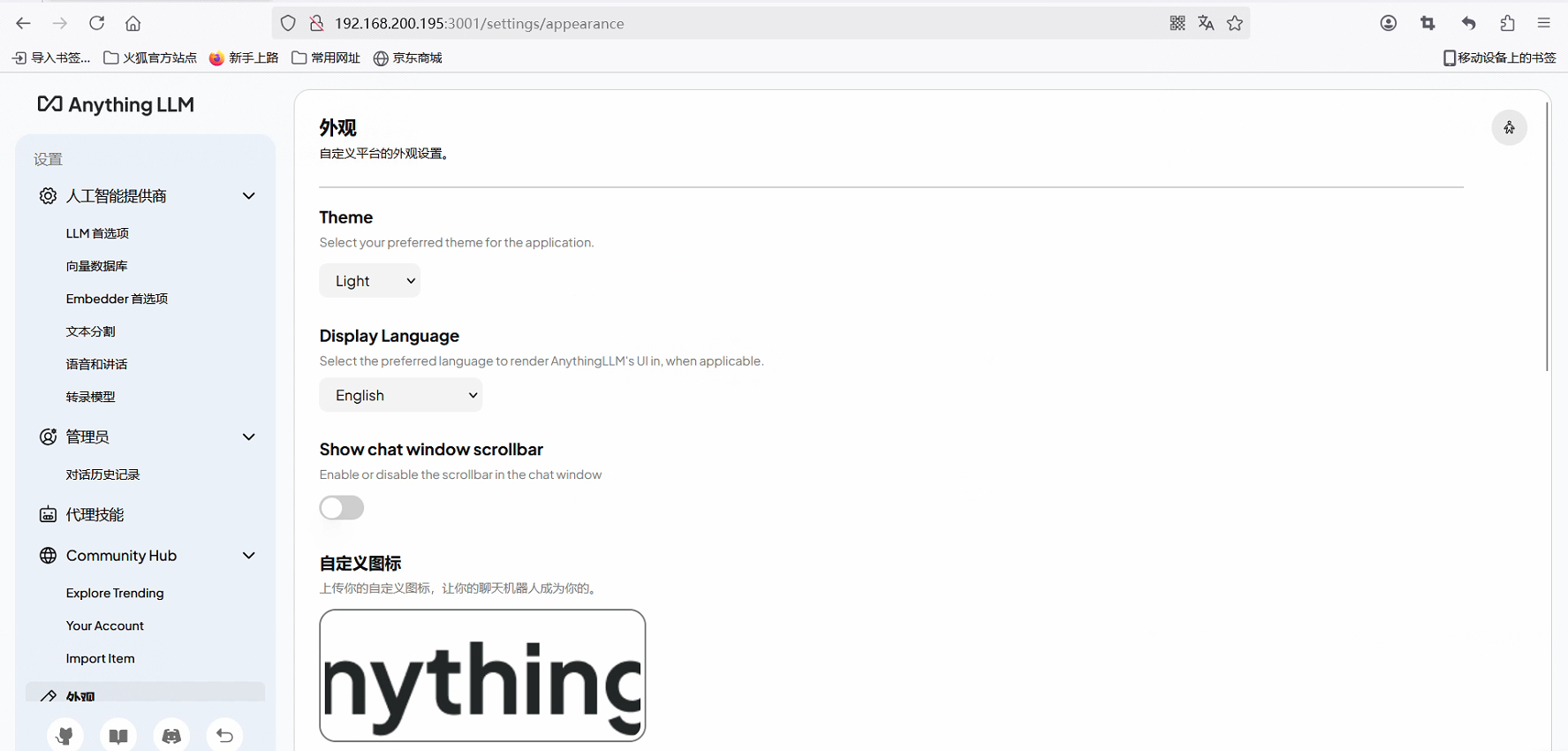
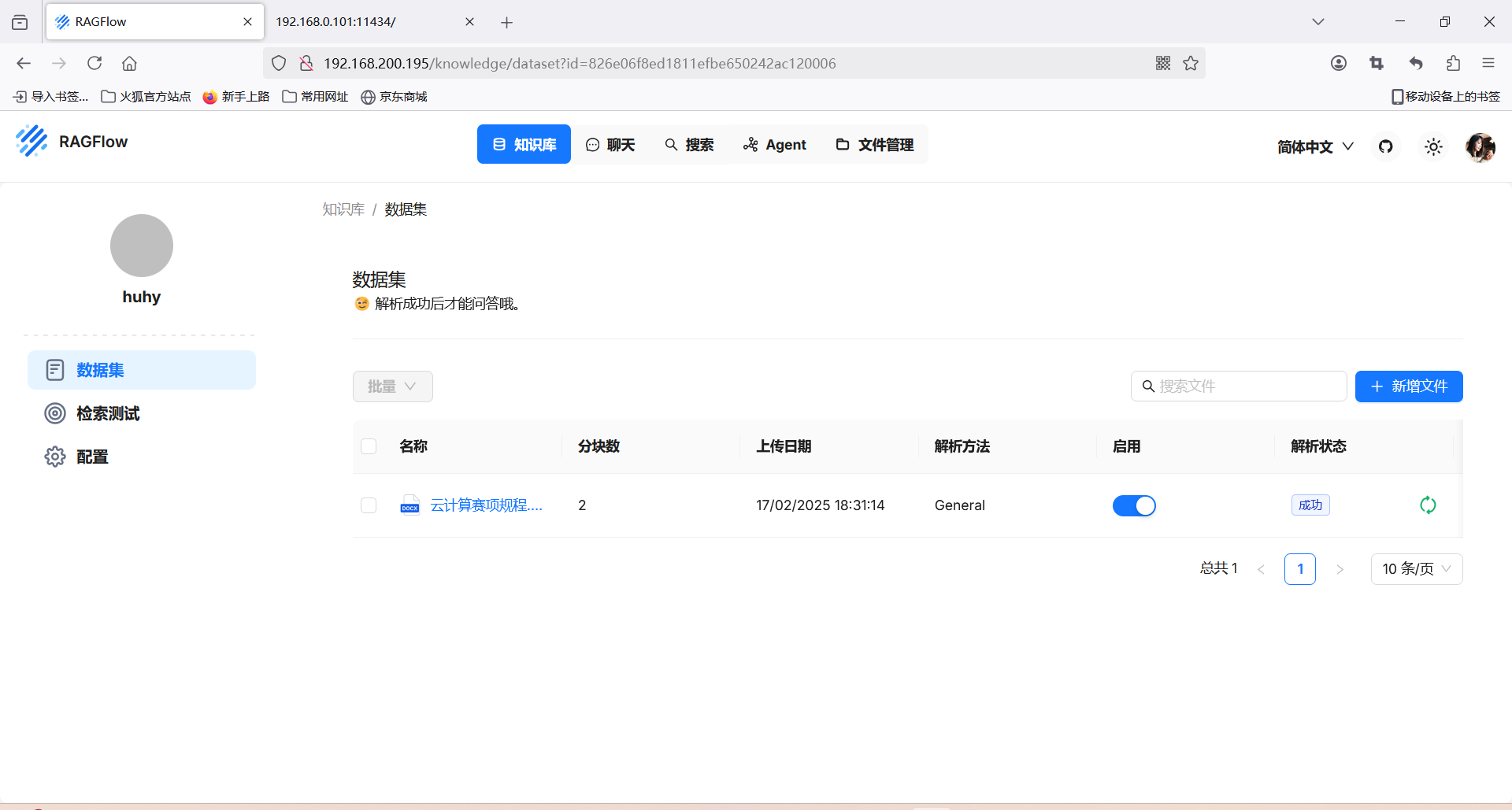
配置本地知识库
unzip ragflow-main.zip cd ragflow-main/
默认使用不带嵌入模型的镜像
root@huhy:~/ragflow-main# cat docker/.env | grep RAGFLOW_IMAGE RAGFLOW_IMAGE=infiniflow/ragflow:v0.16.0-slim # RAGFLOW_IMAGE=infiniflow/ragflow:v0.16.0 # RAGFLOW_IMAGE=swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:nightly-slim # RAGFLOW_IMAGE=registry.cn-hangzhou.aliyuncs.com/infiniflow/ragflow:nightly-slim # RAGFLOW_IMAGE=swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:nightly # RAGFLOW_IMAGE=registry.cn-hangzhou.aliyuncs.com/infiniflow/ragflow:nightly
前端界面访问:http://IP
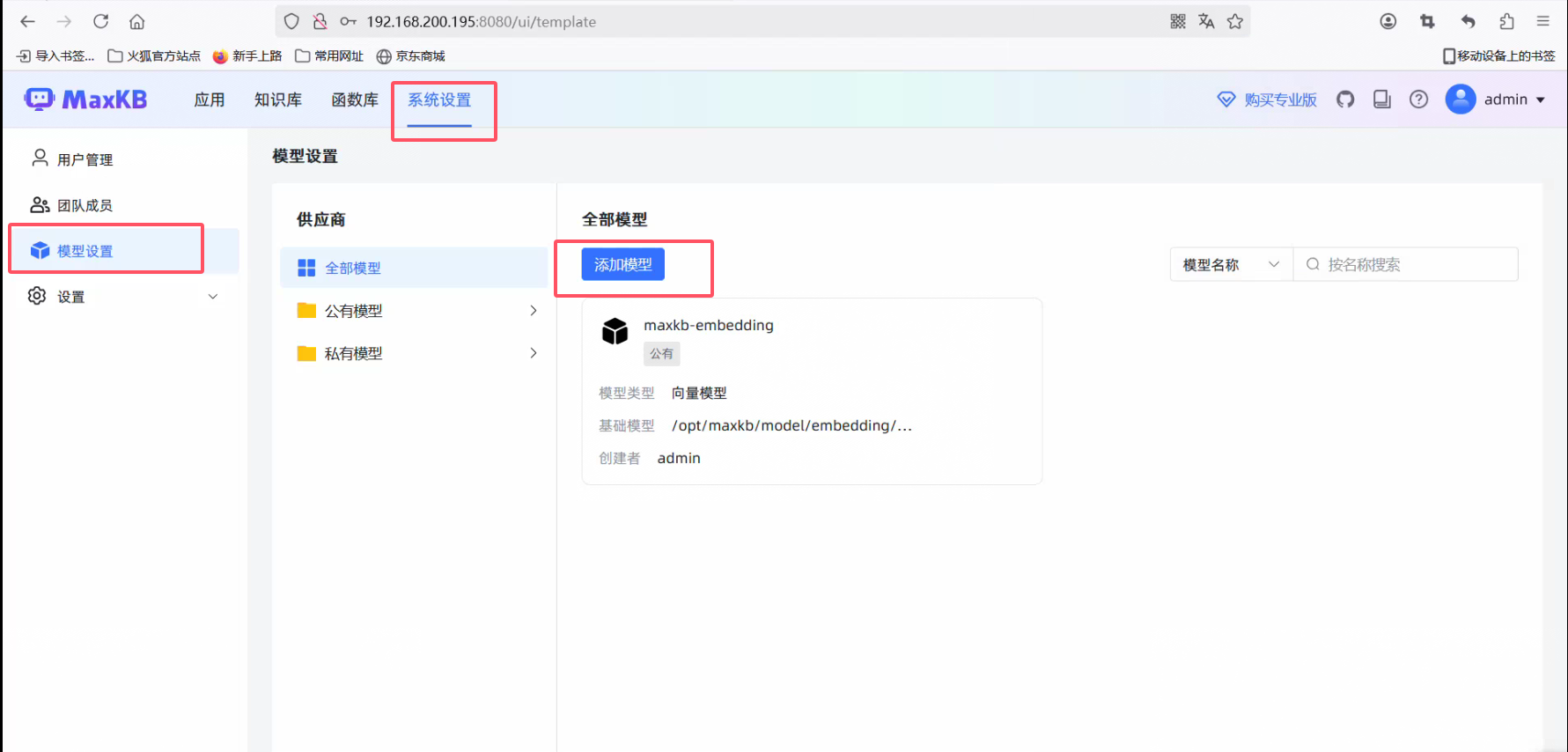
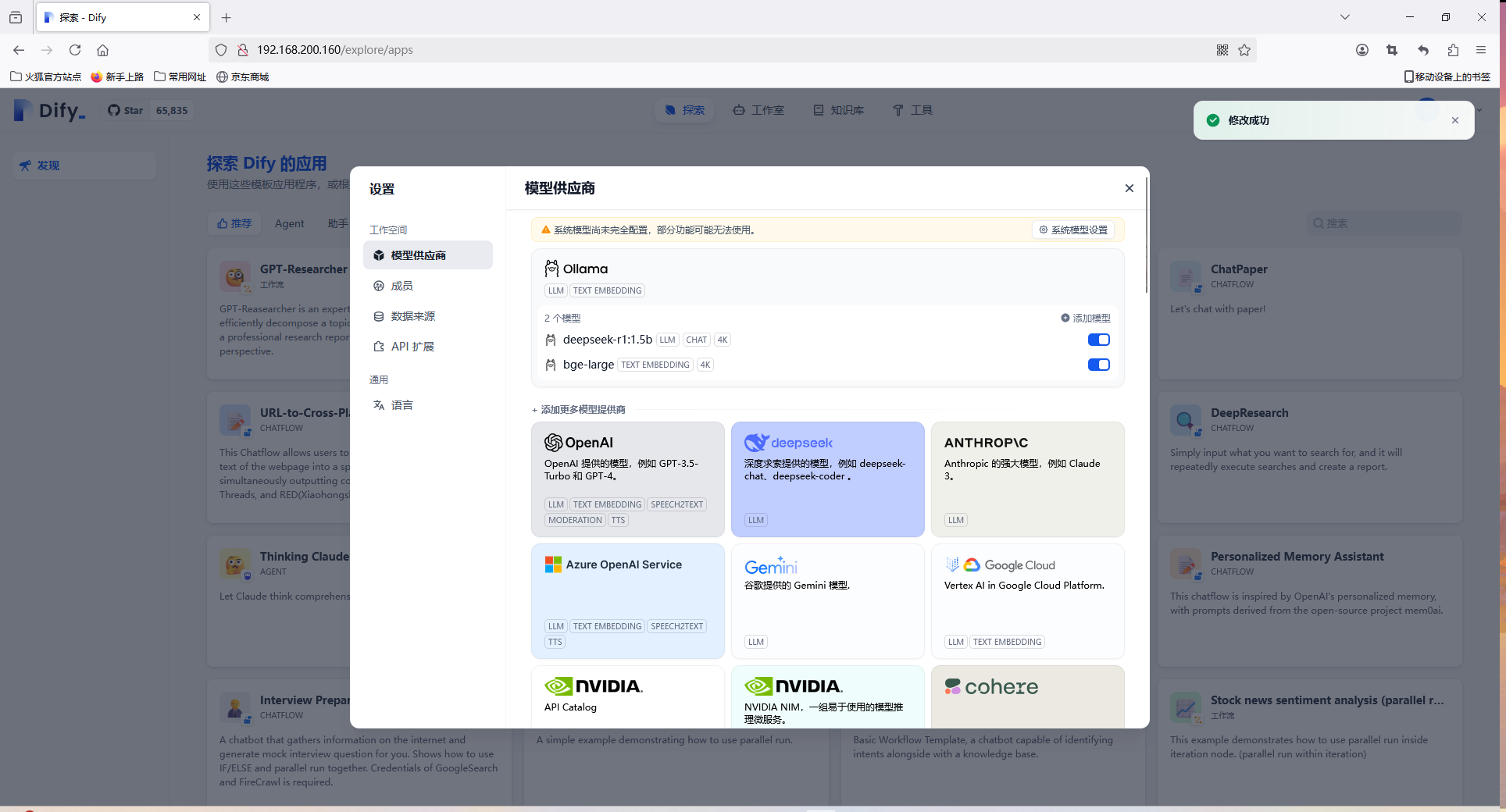
添加模型
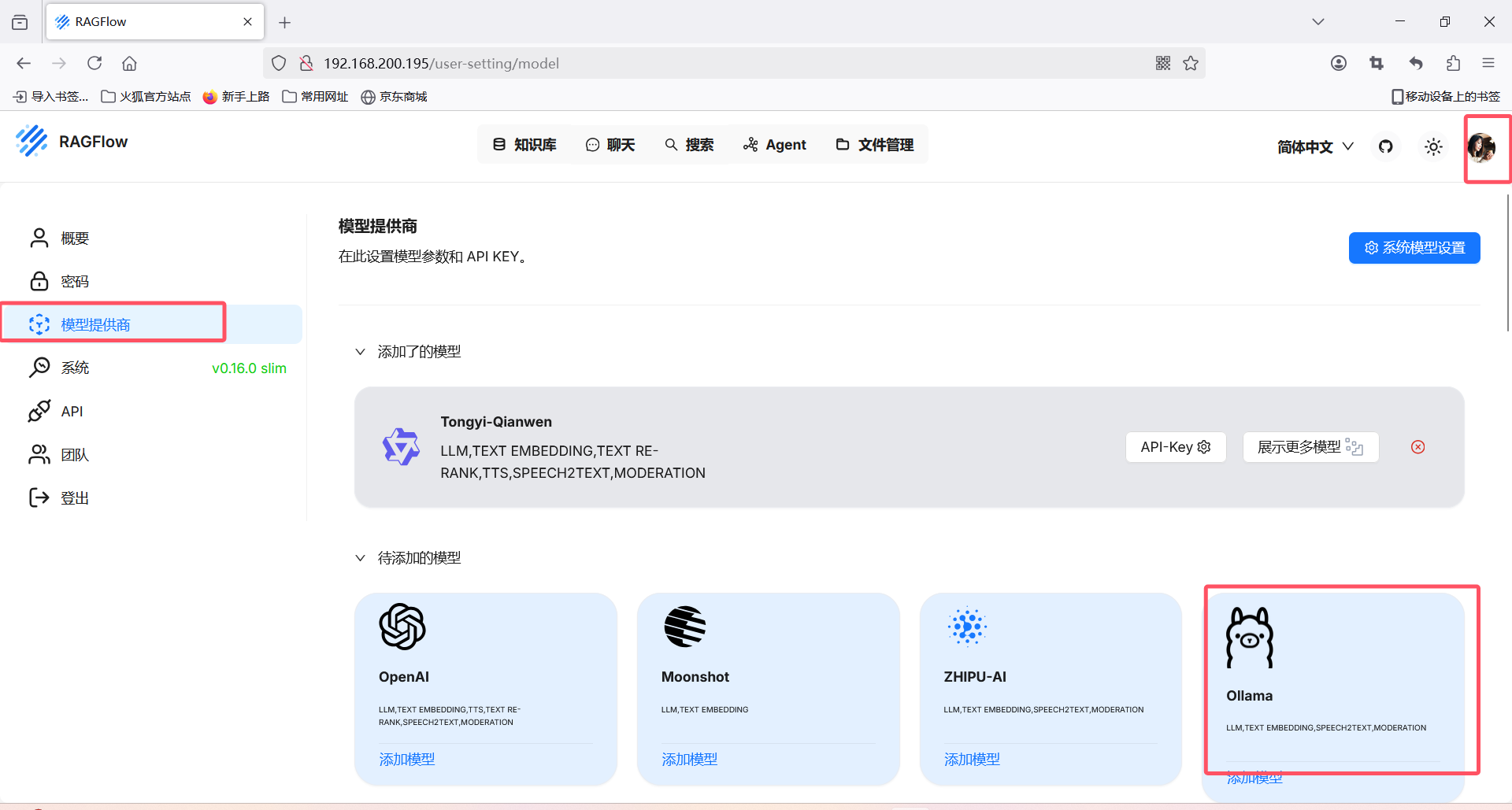
添加系统模型
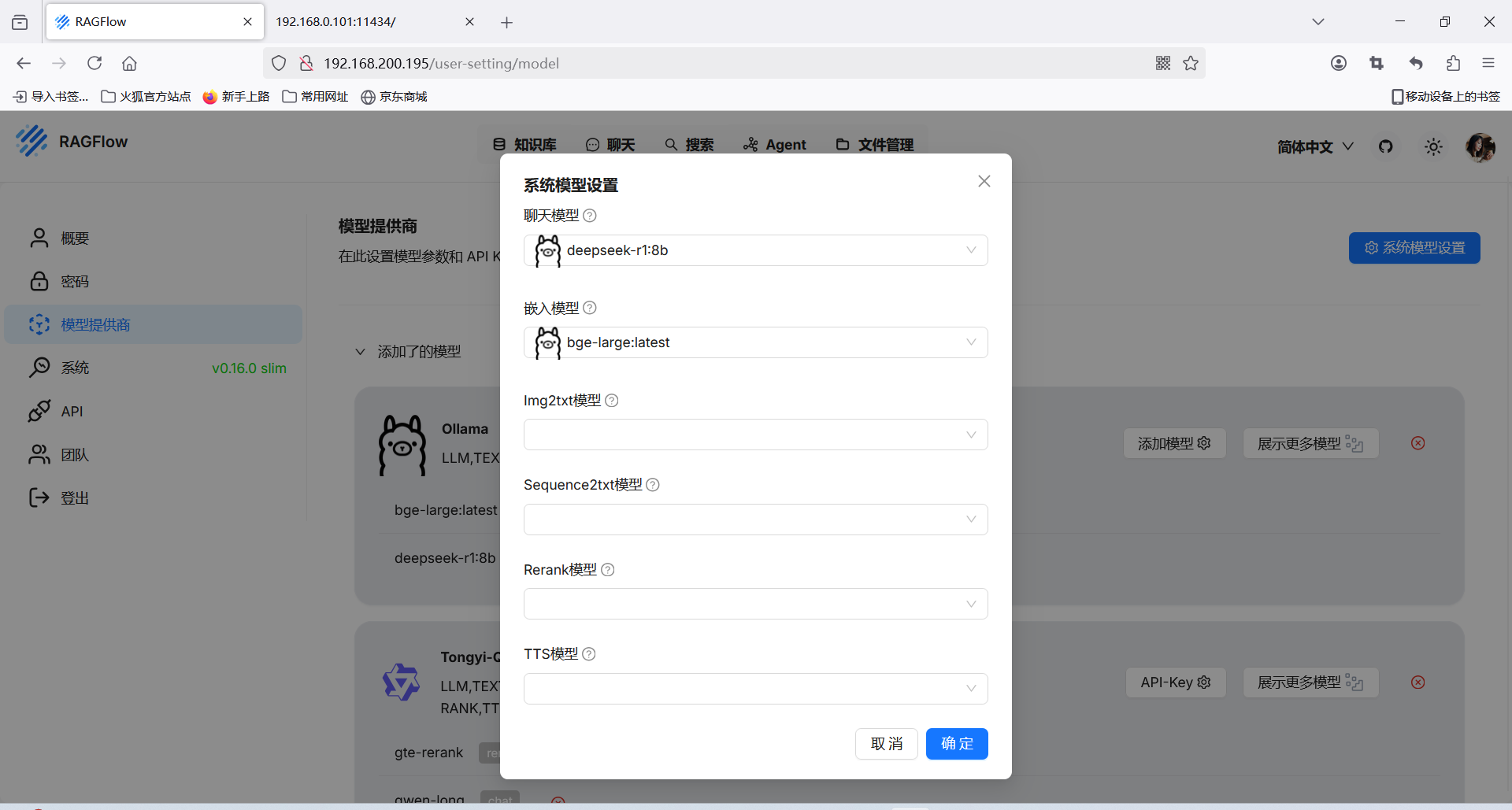
配置本地知识库
上传后点击解析
新建助理
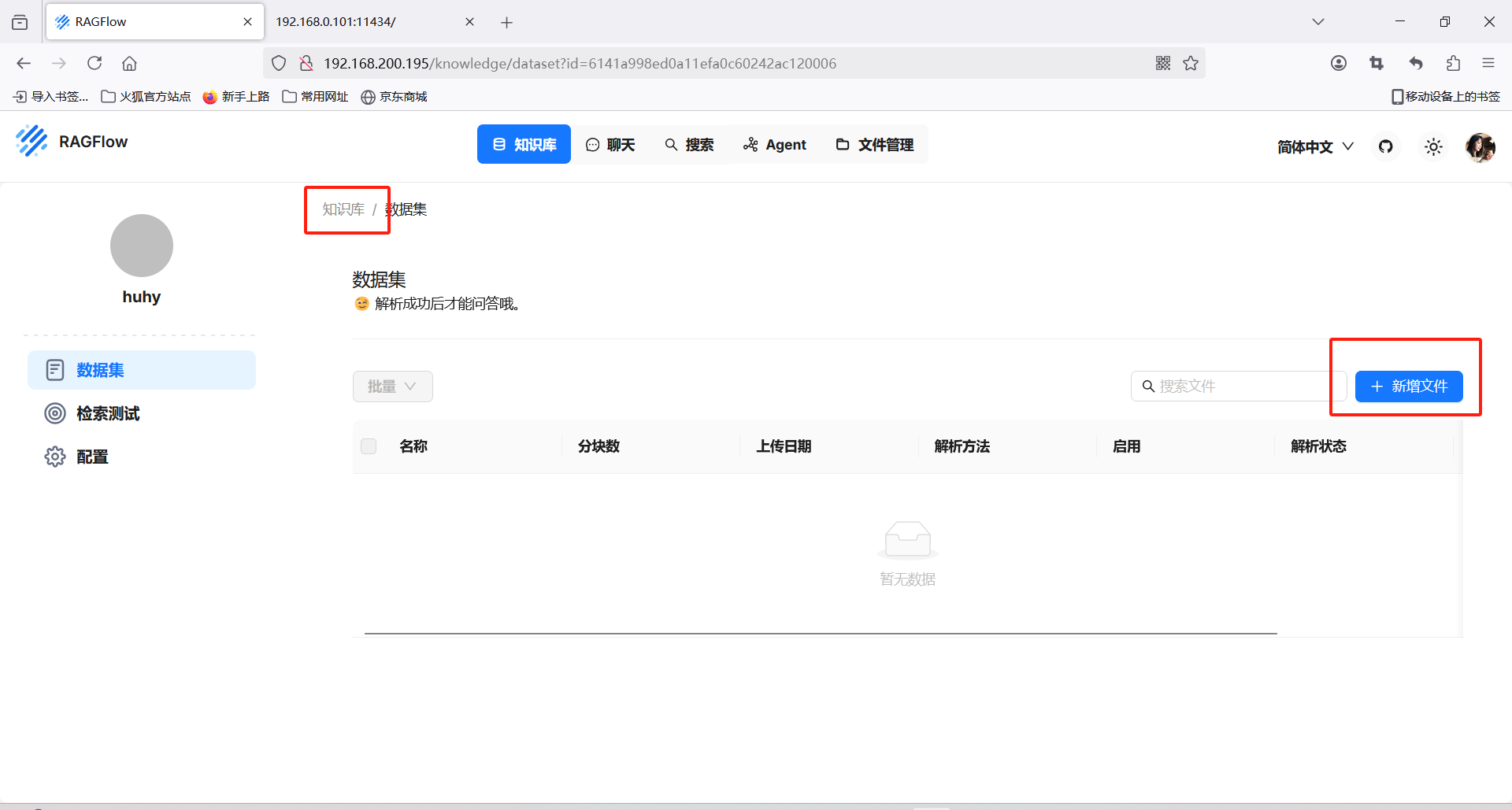
创建知识库后添加文件
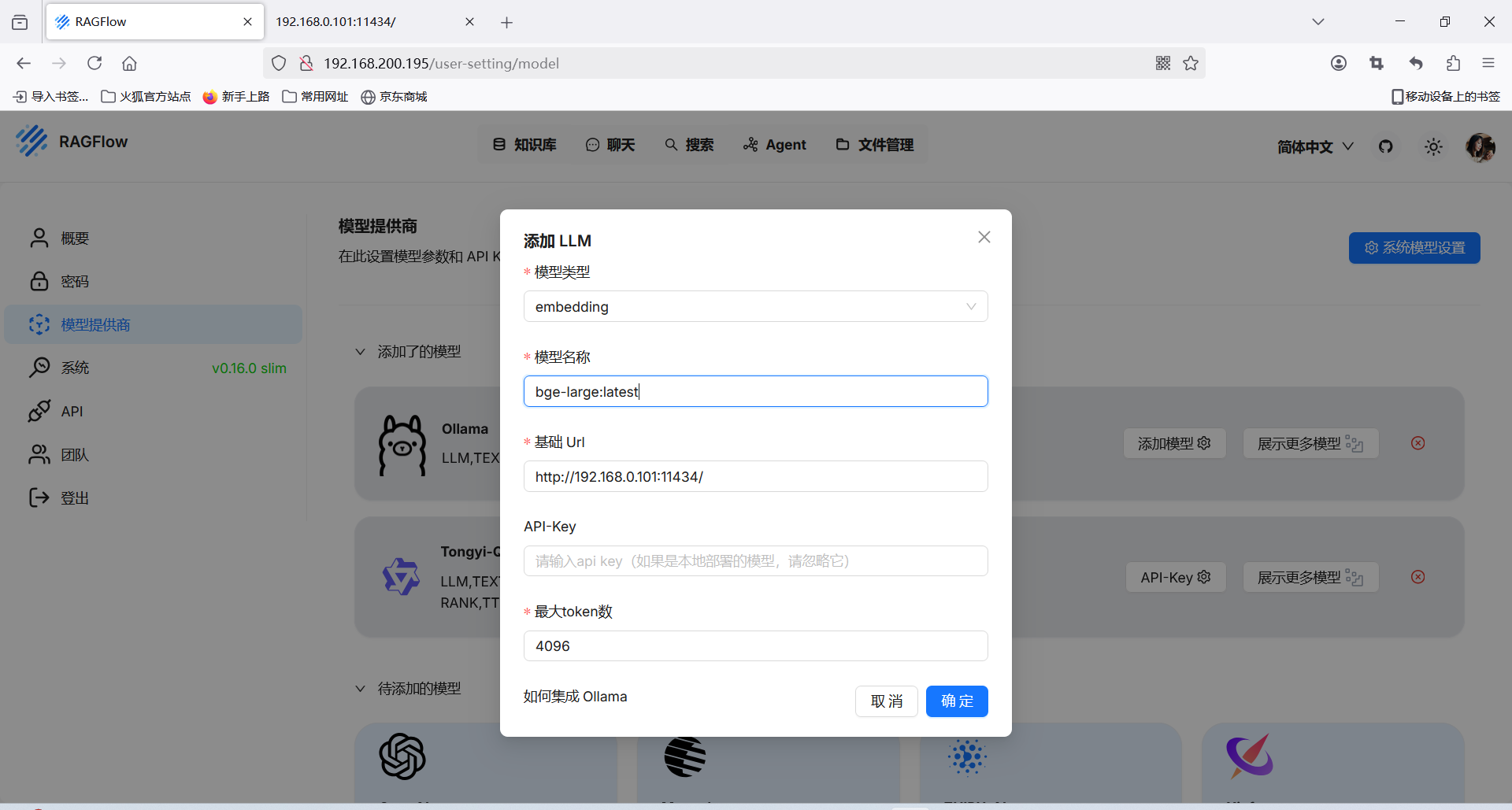
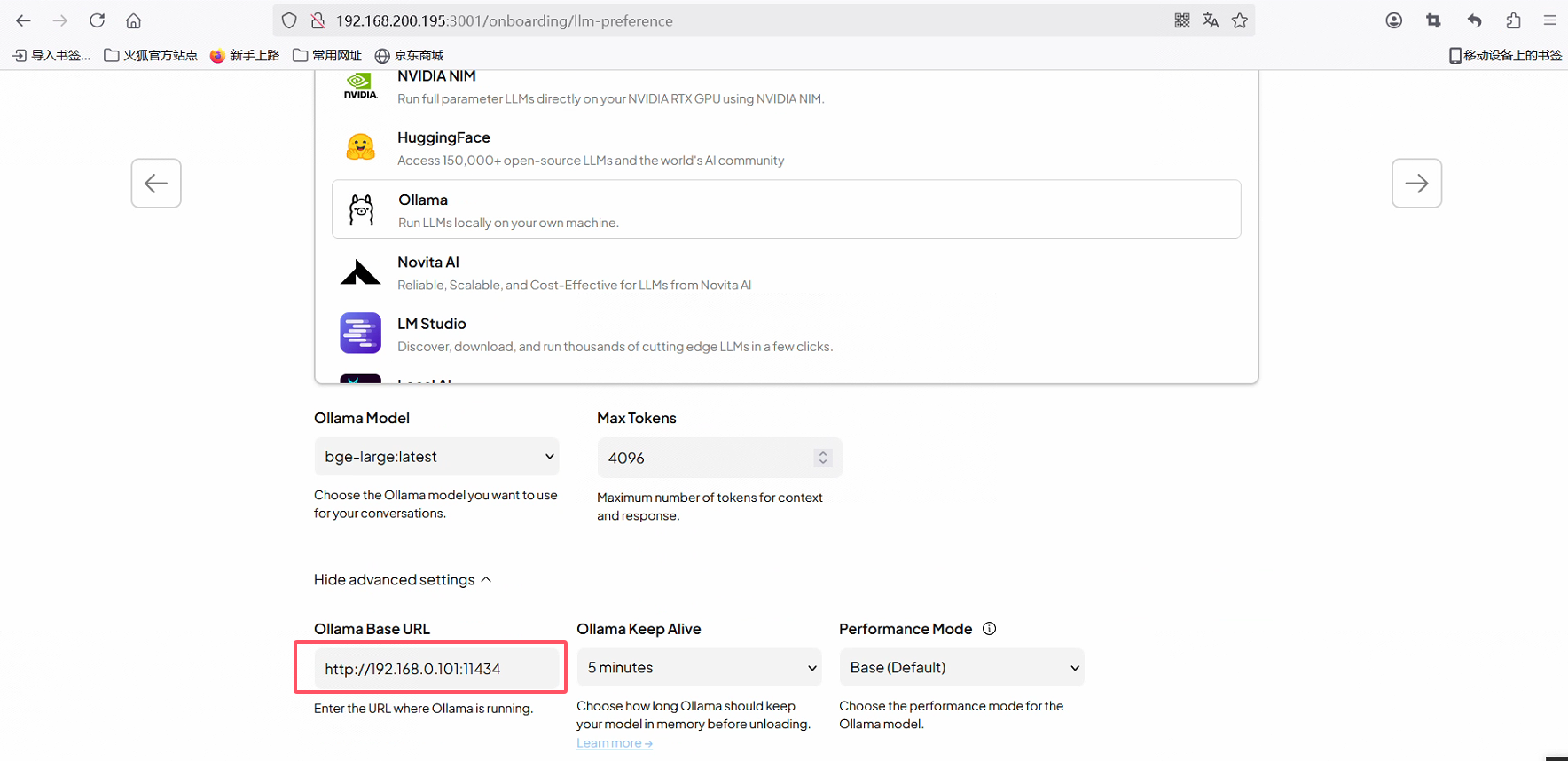
配置ollama
创建账户
启动Compose文件
docker compose -f docker/docker-compose.yml up -d
root@huhy:~/ragflow-main# docker compose -f docker/docker-compose.yml ps WARN[0000] The "HF_ENDPOINT" variable is not set. Defaulting to a blank string. WARN[0000] The "MACOS" variable is not set. Defaulting to a blank string. NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS ragflow-es-01 elasticsearch:8.11.3 "/bin/tini -- /usr/l…" es01 3 minutes ago Up 3 minutes (healthy) 9300/tcp, 0.0.0.0:1200->9200/tcp, [::]:1200->9200/tcp ragflow-minio quay.io/minio/minio:RELEASE.2023-12-20T01-00-02Z "/usr/bin/docker-ent…" minio 3 minutes ago Up 3 minutes 0.0.0.0:9000-9001->9000-9001/tcp, :::9000-9001->9000-9001/tcp ragflow-mysql mysql:8.0.39 "docker-entrypoint.s…" mysql 3 minutes ago Up 3 minutes (healthy) 33060/tcp, 0.0.0.0:5455->3306/tcp, [::]:5455->3306/tcp ragflow-redis valkey/valkey:8 "docker-entrypoint.s…" redis 3 minutes ago Up 3 minutes 0.0.0.0:6379->6379/tcp, :::6379->6379/tcp ragflow-server infiniflow/ragflow:v0.16.0-slim "./entrypoint.sh" ragflow 3 minutes ago Up 3 minutes 0.0.0.0:80->80/tcp, :::80->80/tcp, 0.0.0.0:443->443/tcp, :::443->443/tcp, 0.0.0.0:9380->9380/tcp, :::9380->9380/tcp
RAGFlow 版本镜像的描述:
RAGFlow镜像标签 镜像大小 (GB) 有嵌入模型和 Python 包吗? 稳定性 v0.16.0 ≈9 ✔️ 稳定版本 v0.16.0-slim ≈2 ❌ 稳定版本 nightly ≈9 ✔️ 不稳定的夜间构建 nightly-slim ≈2 ❌ 不稳定的夜间构建 选中文档后移动到工作区huhy保存即可
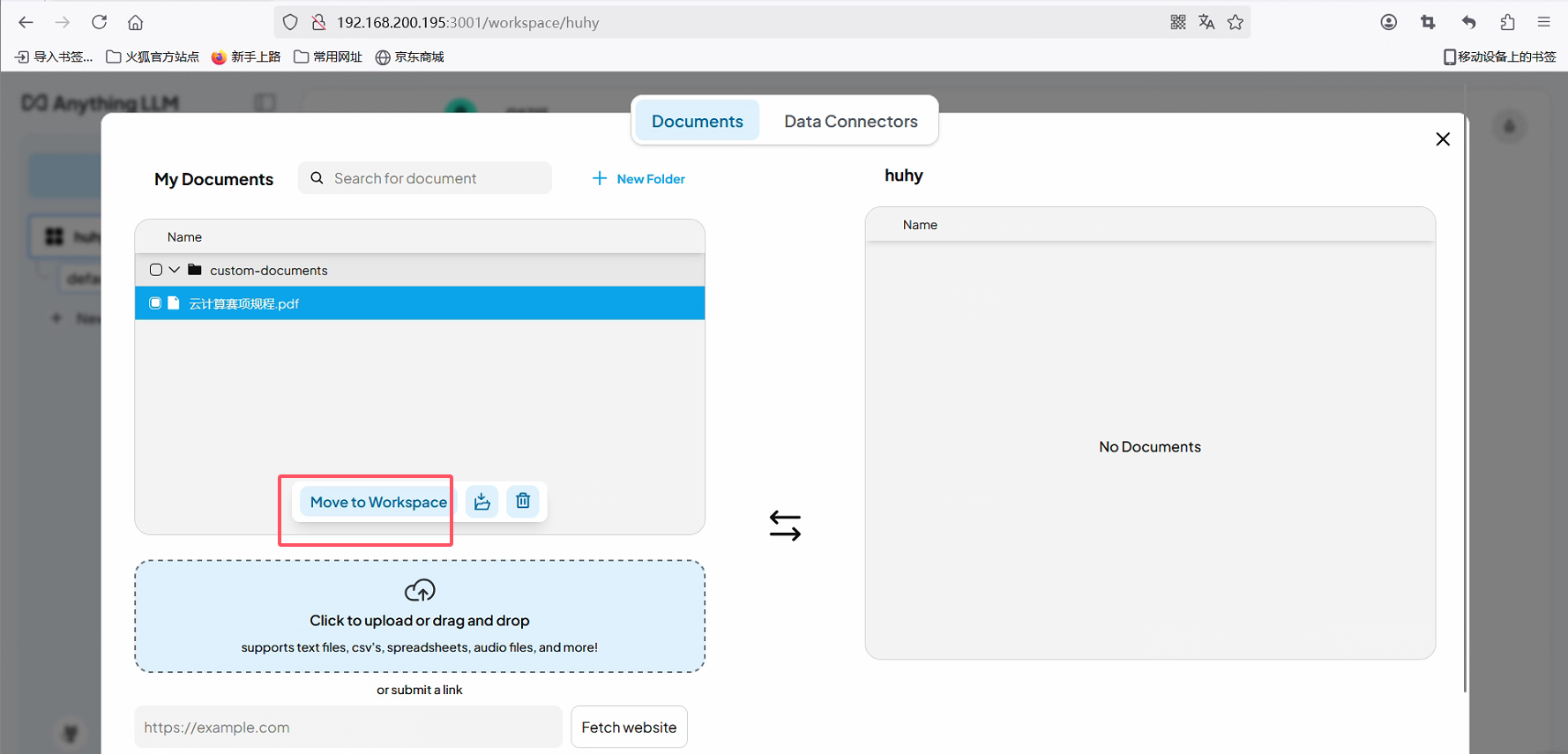
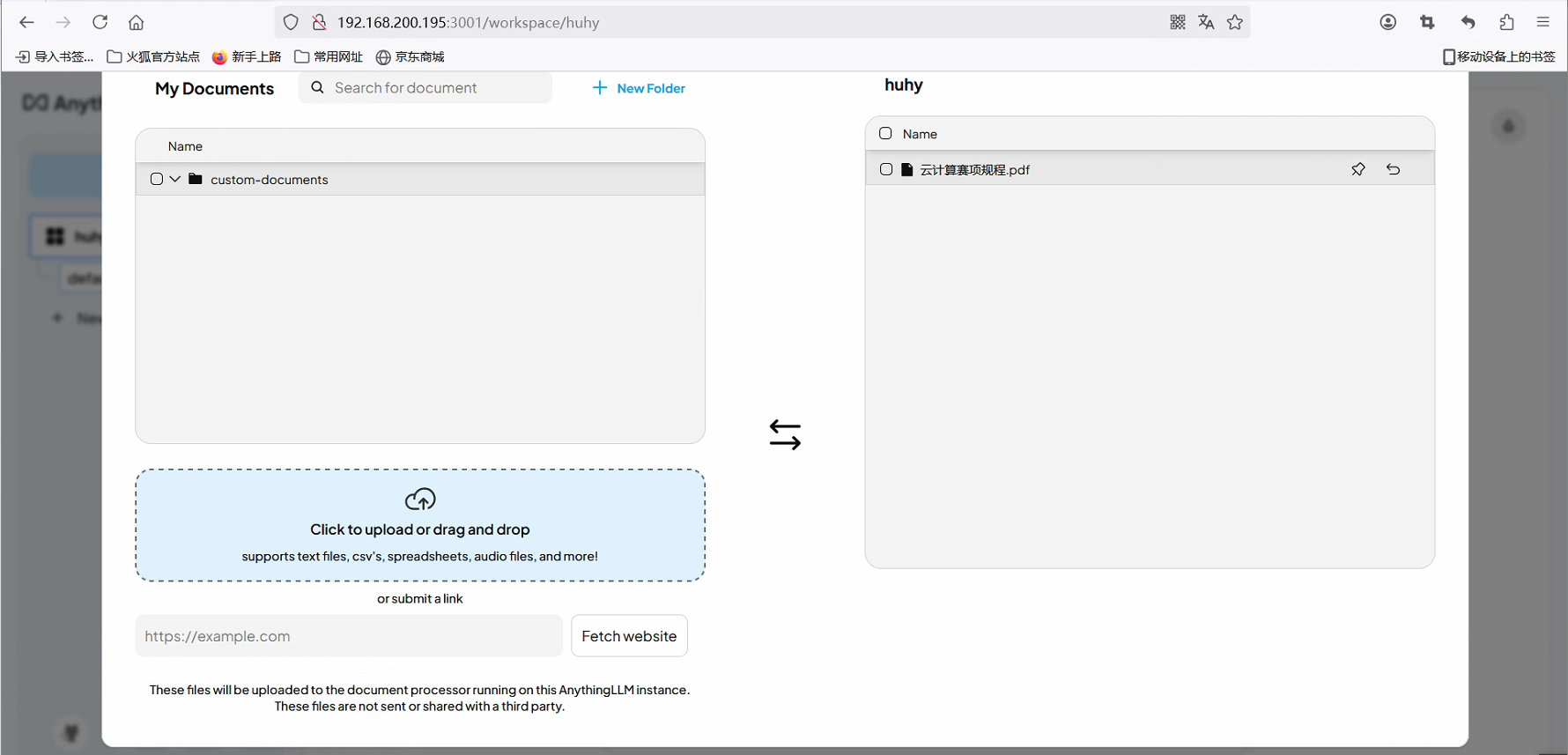
下载软件包
git clone https://github.com/infiniflow/ragflow.git
如果网络问题,可界面下载上传
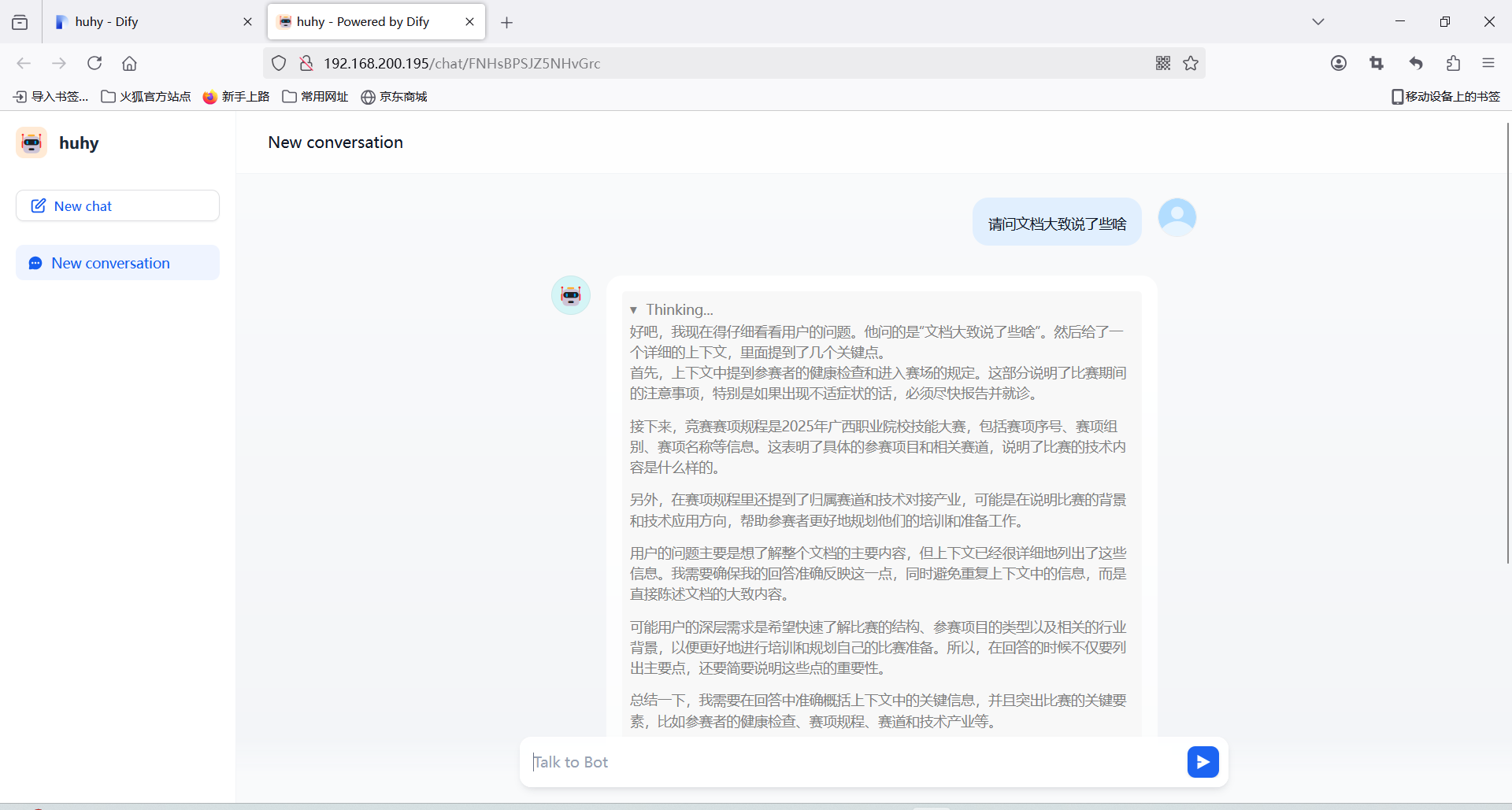
开始根据知识库问答
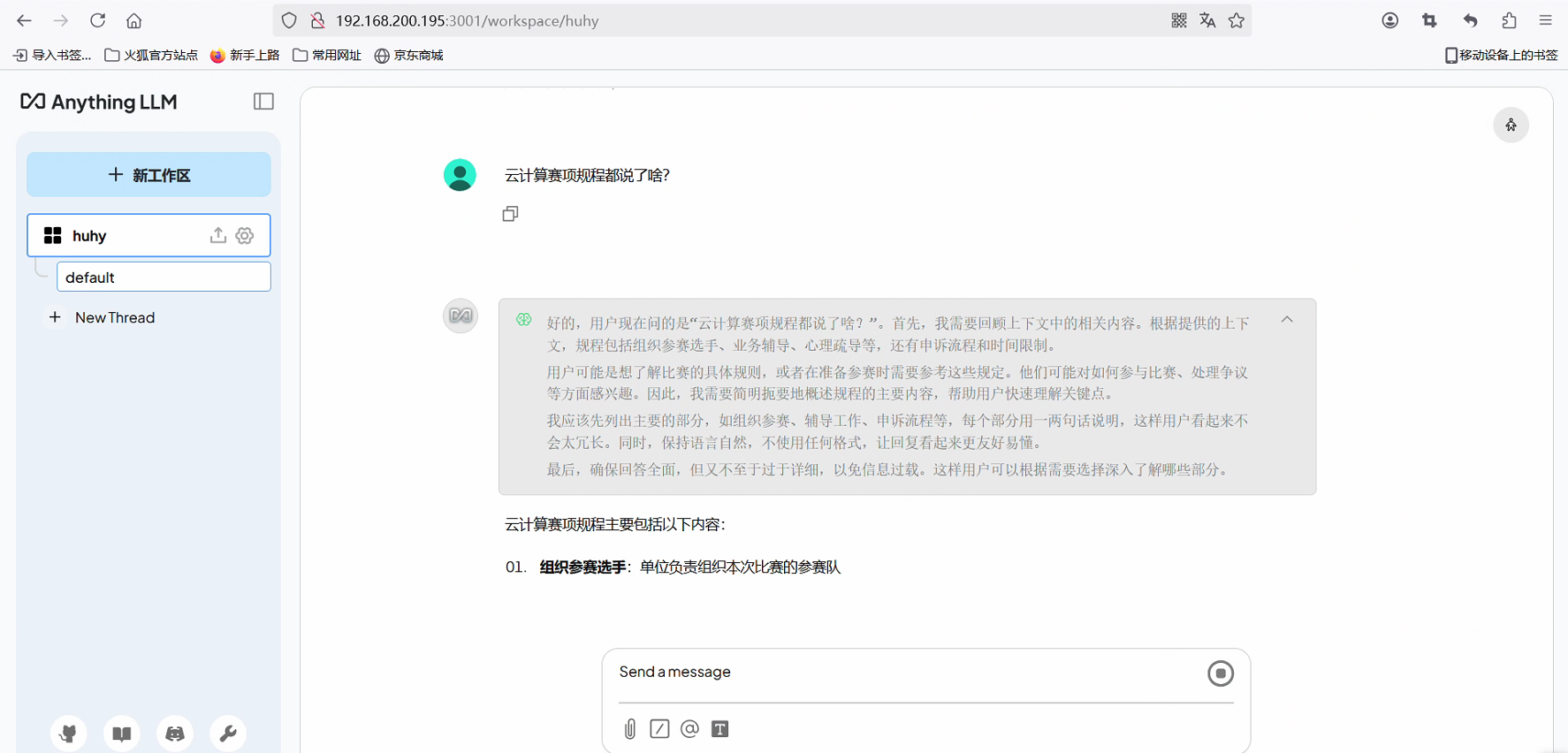
Docker安装RAGFlow
GitHub官网
RAGFlow是一款基于深度文档理解的开源 RAG(检索增强生成)引擎。它为任何规模的企业提供简化的 RAG 工作流程,结合 LLM(大型语言模型)提供真实的问答功能,并以来自各种复杂格式数据的合理引证为后盾。
官方文档
上传文档搭建本地知识库
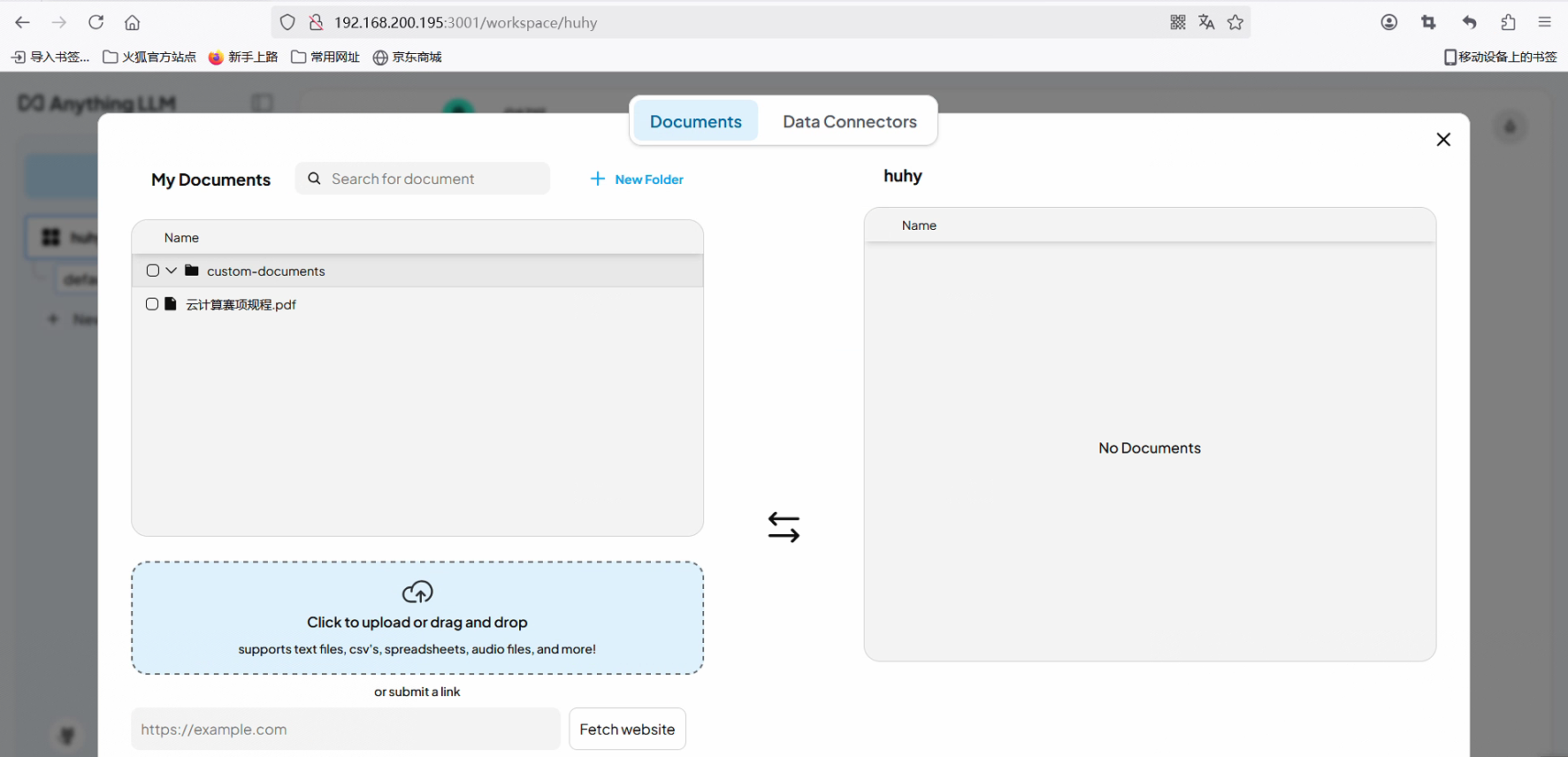
点击左下角小扳手进入设置页面
配置Ollaman连接
配置用户设置
启动容器
docker run -d -p 3001:3001 \ --cap-add SYS_ADMIN \ -v ${STORAGE_LOCATION}:/app/server/storage \ -v ${STORAGE_LOCATION}/.env:/app/server/.env \ -e STORAGE_DIR="/app/server/storage" \ mintplexlabs/anythingllmroot@huhy:~# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 97d2a4adf7d4 mintplexlabs/anythingllm "/bin/bash /usr/loca…" About an hour ago Up 42 seconds (healthy) 0.0.0.0:3001->3001/tcp, :::3001->3001/tcp sweet_spence
AnythingLLM的一些酷炫特性:
多用户实例支持和权限管理
工作区内的智能体Agent(浏览网页、运行代码等)
为您的网站定制的可嵌入聊天窗口
支持多种文档类型(PDF、TXT、DOCX等)
通过简单的用户界面管理向量数据库中的文档
两种对话模式:聊天和查询。聊天模式保留先前的对话记录。查询模式则是是针对您的文档做简单问答
聊天中会提供所引用的相应文档内容
100%云部署就绪。
“部署你自己的LLM模型”。
管理超大文档时高效、低耗。只需要一次就可以嵌入(Embedding)一个庞大的文档或文字记录。比其他文档聊天机器人解决方案节省90%的成本。
全套的开发人员API,用于自定义集成!
使用Docker安装部署
官网文档
创建持续化存储目录
export STORAGE_LOCATION=$HOME/anythingllm && \ mkdir -p $STORAGE_LOCATION && \ touch "$STORAGE_LOCATION/.env" && \
继续添加Text Embedding。这是为知识库添加bge-large模型
✅ 语义搜索(Semantic Search)
✅ 智能问答(QA Retrieval)
✅ 知识库增强(RAG)(如 LlamaIndex, LangChain)
✅ 文本相似度匹配(Sentence Similarity)
✅ 推荐系统(Recommendation Systems)
PS C:\Users\huhy> ollama pull bge-large pulling manifest pulling 92b37e50807d... 100% ▕████████████████████████████████████████████████████████▏ 670 MB pulling a406579cd136... 100% ▕████████████████████████████████████████████████████████▏ 1.1 KB pulling 917eef6a95d7... 100% ▕████████████████████████████████████████████████████████▏ 337 B verifying sha256 digest writing manifest success
Dify官网配置说明
最终添加如下:
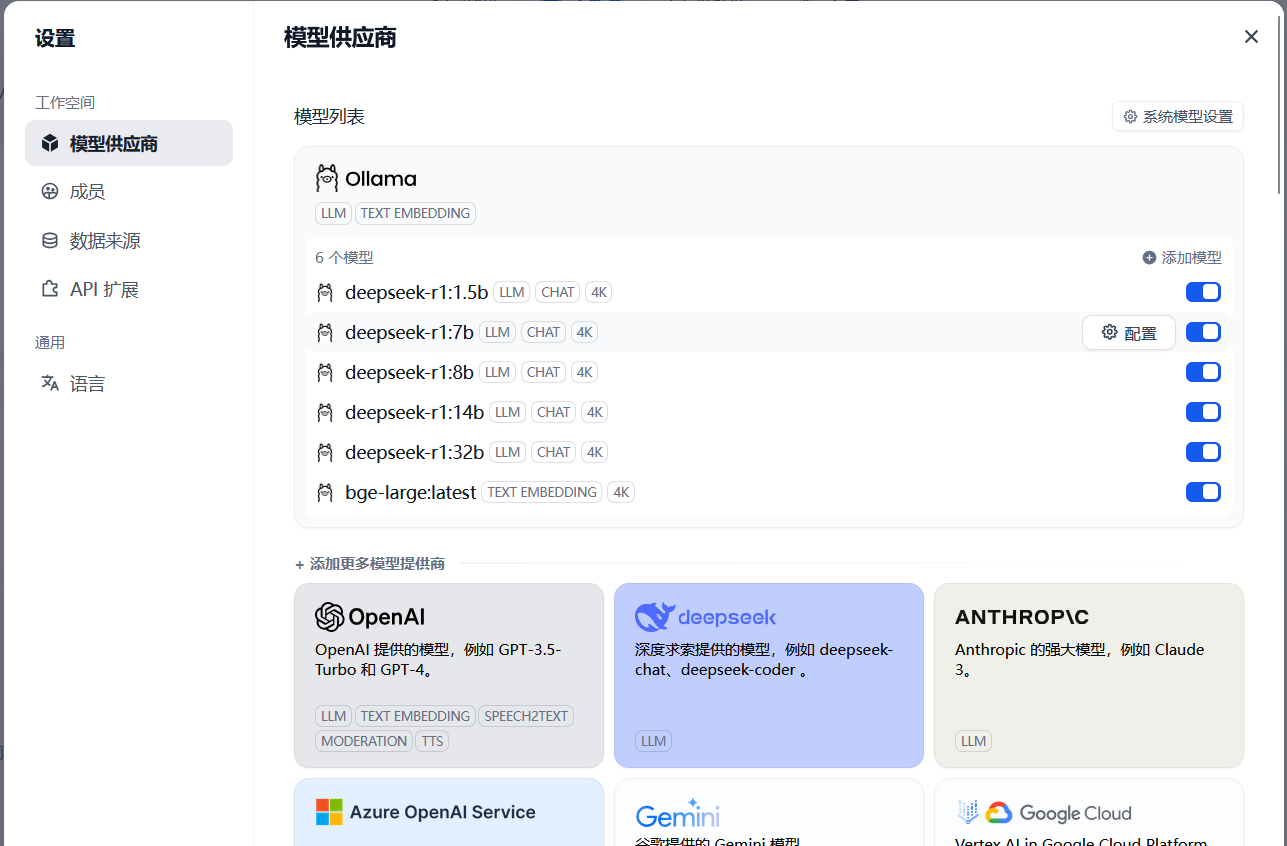
配置本地知识库
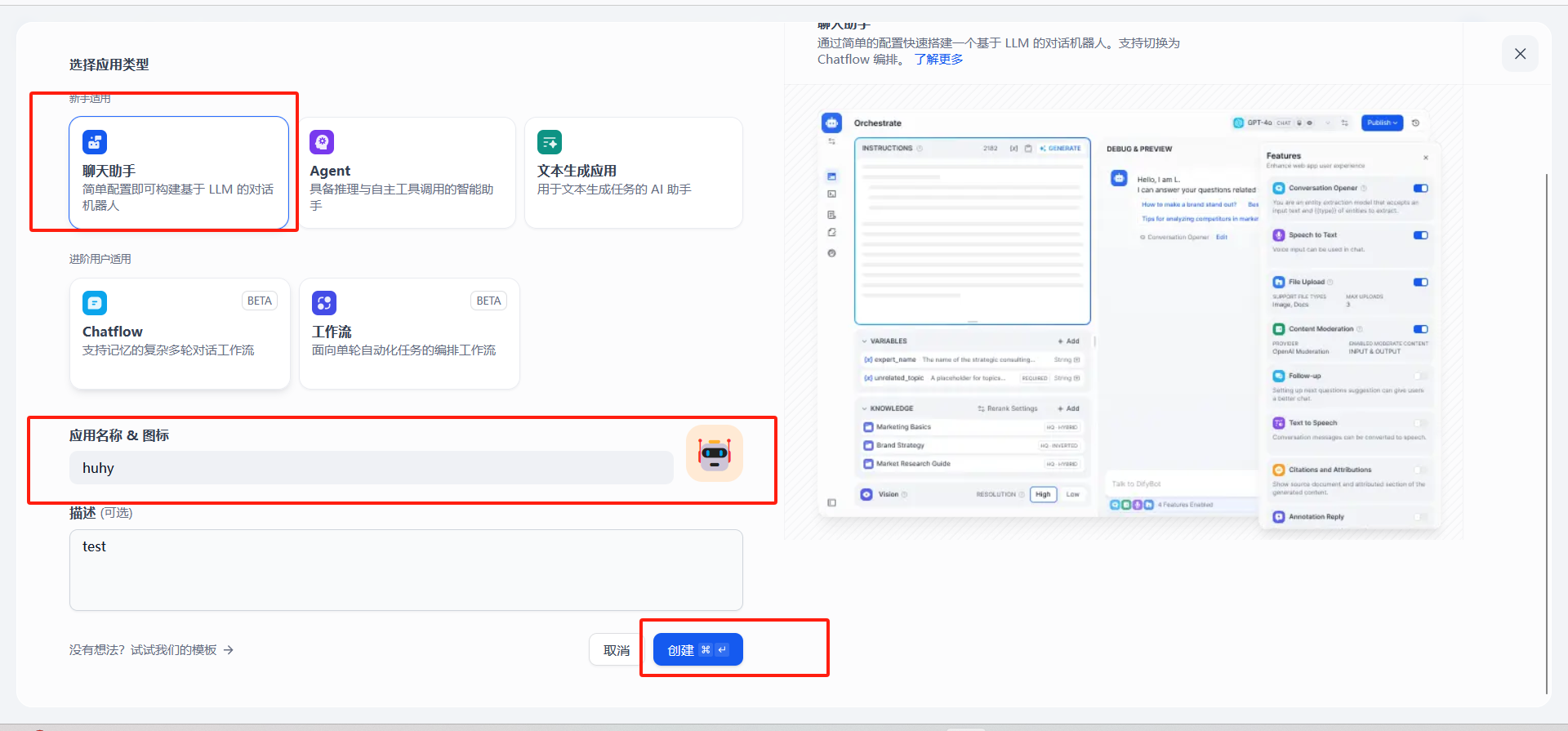
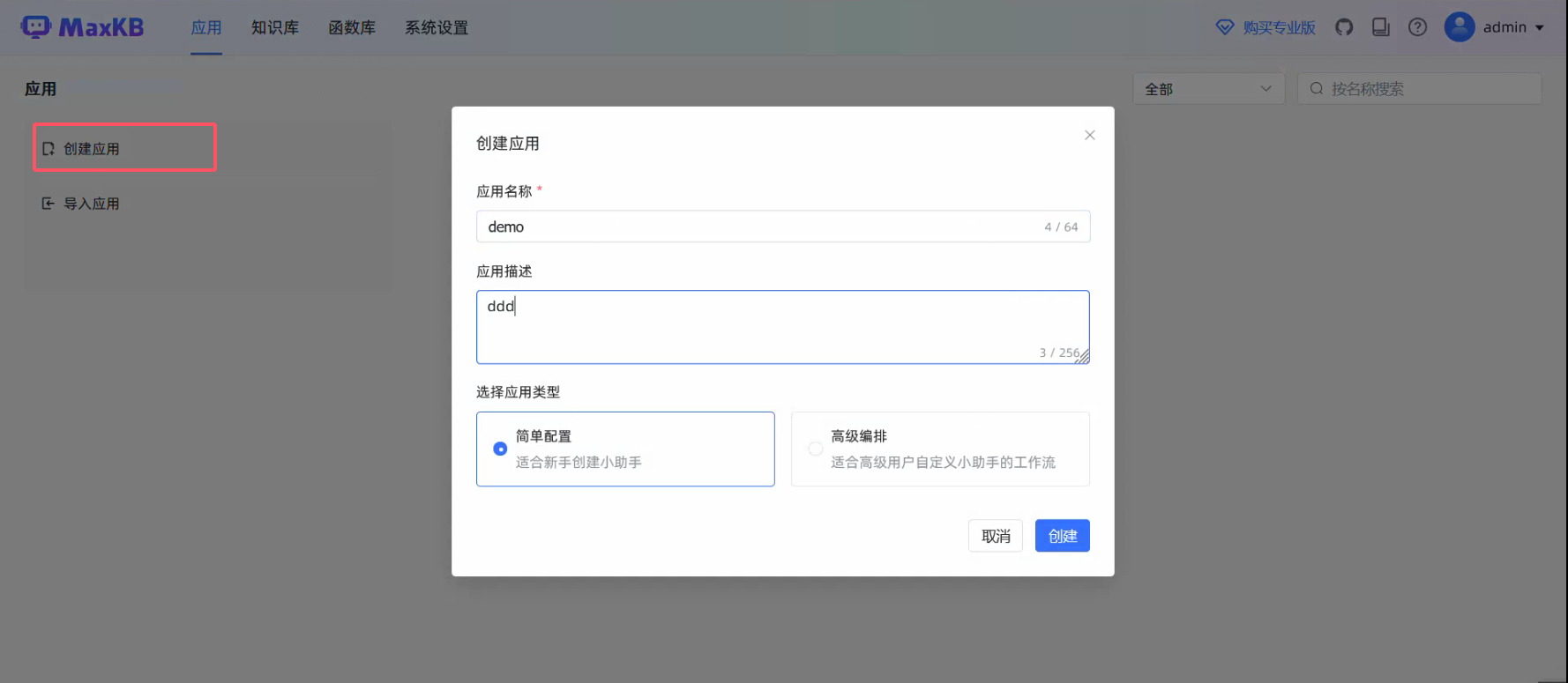
创建应用
添加上下问,导入本地知识库
对比参数模型
发布聊天:可以根据场景选择发布方式
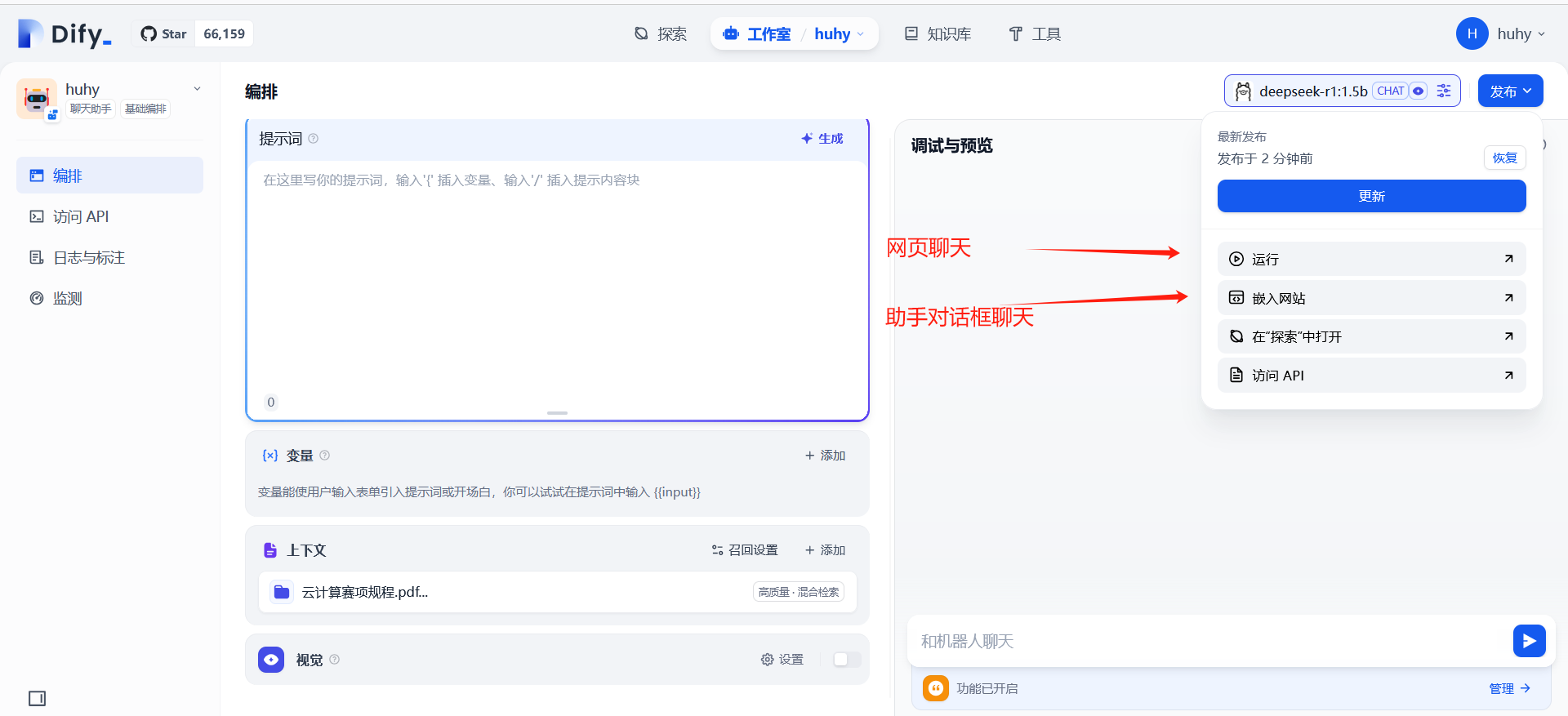
选择聊天助手
注意选择Embedding 模型后保存下一步
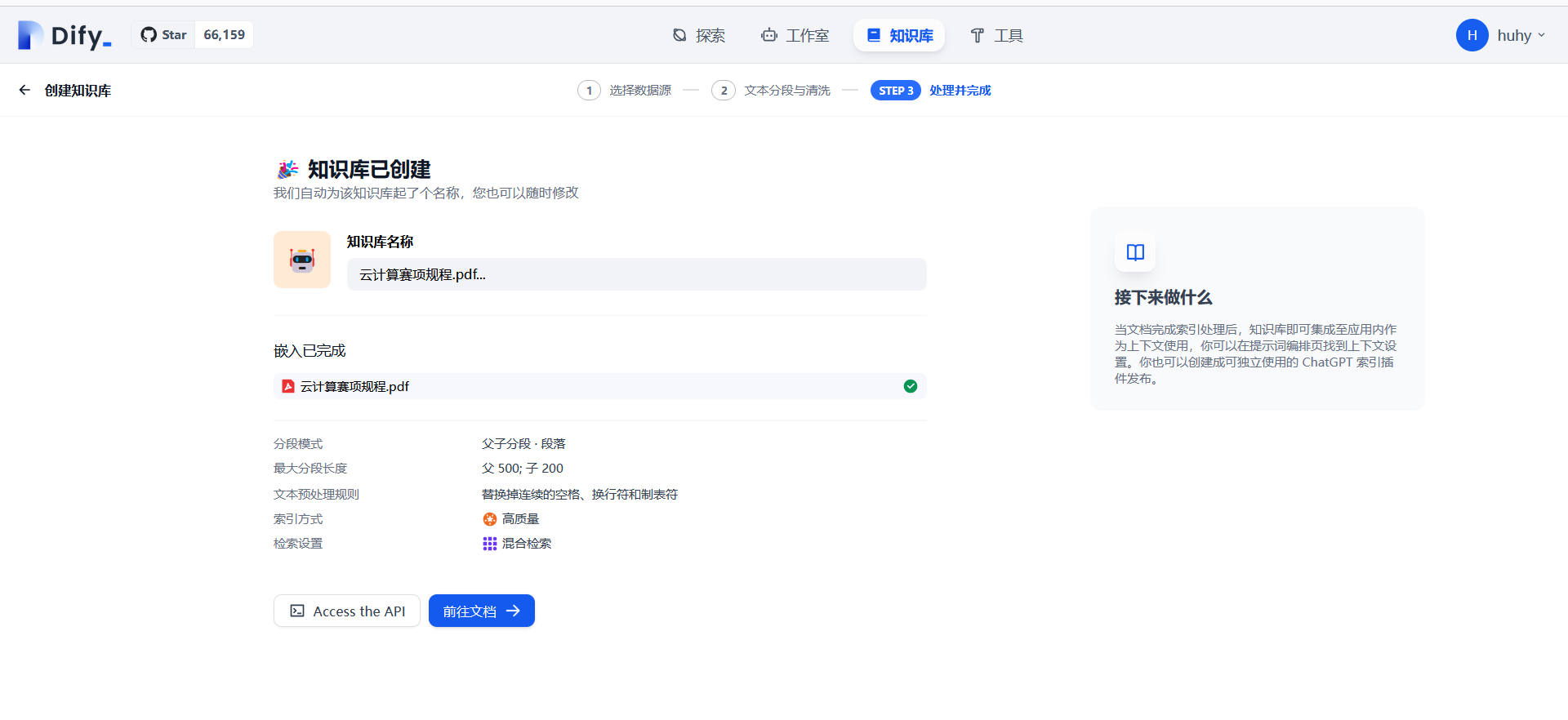
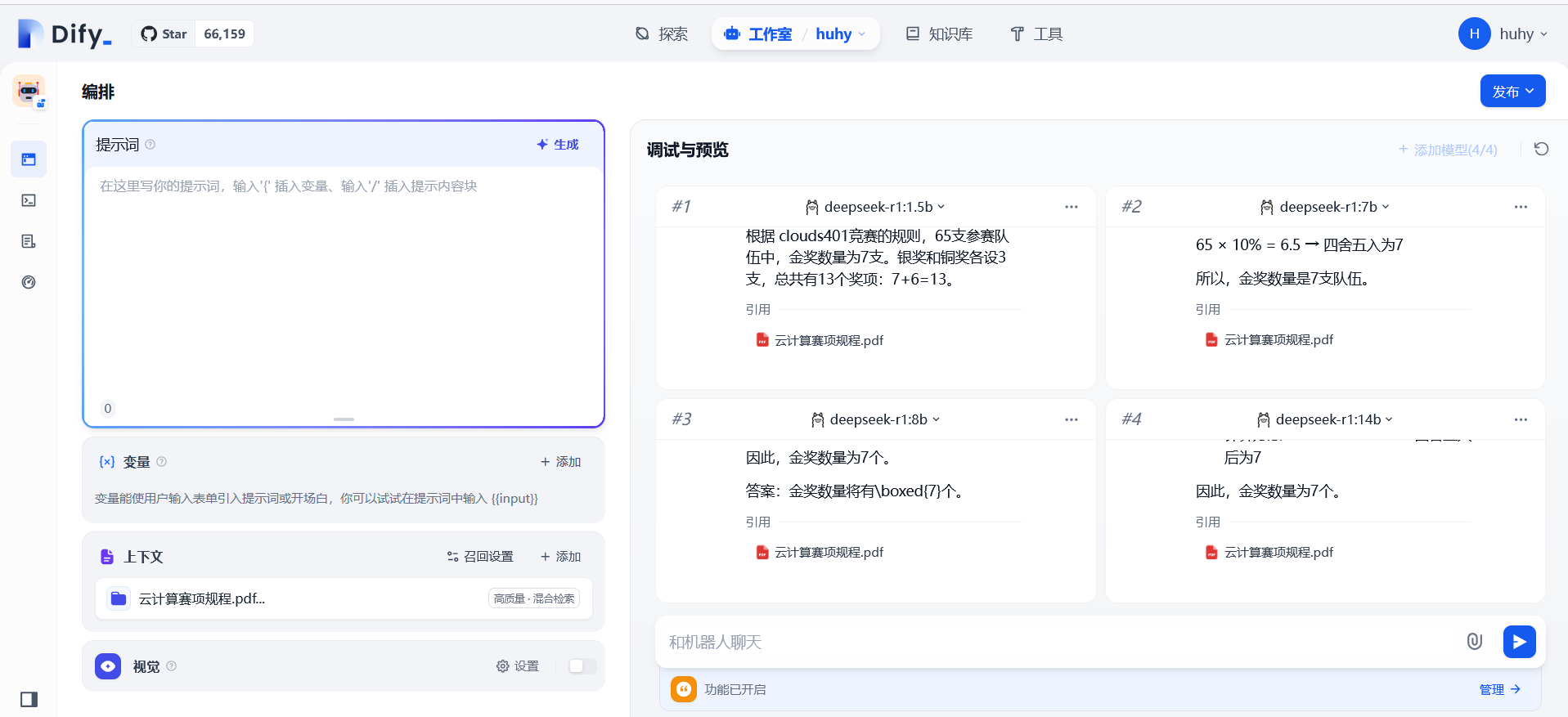
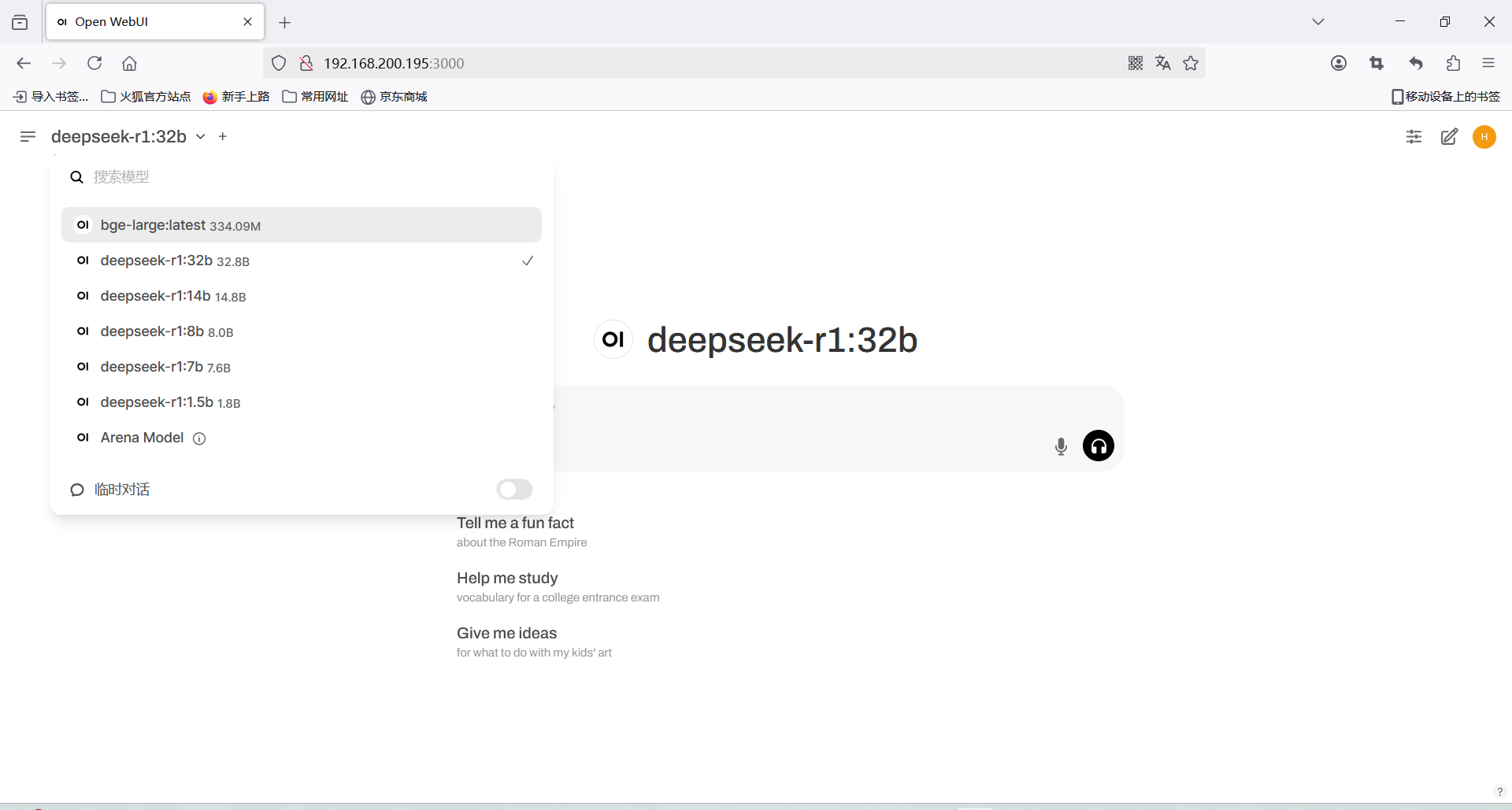
同时测试1.5b、7b、8b、14b模型
1:对四个模型同时提问
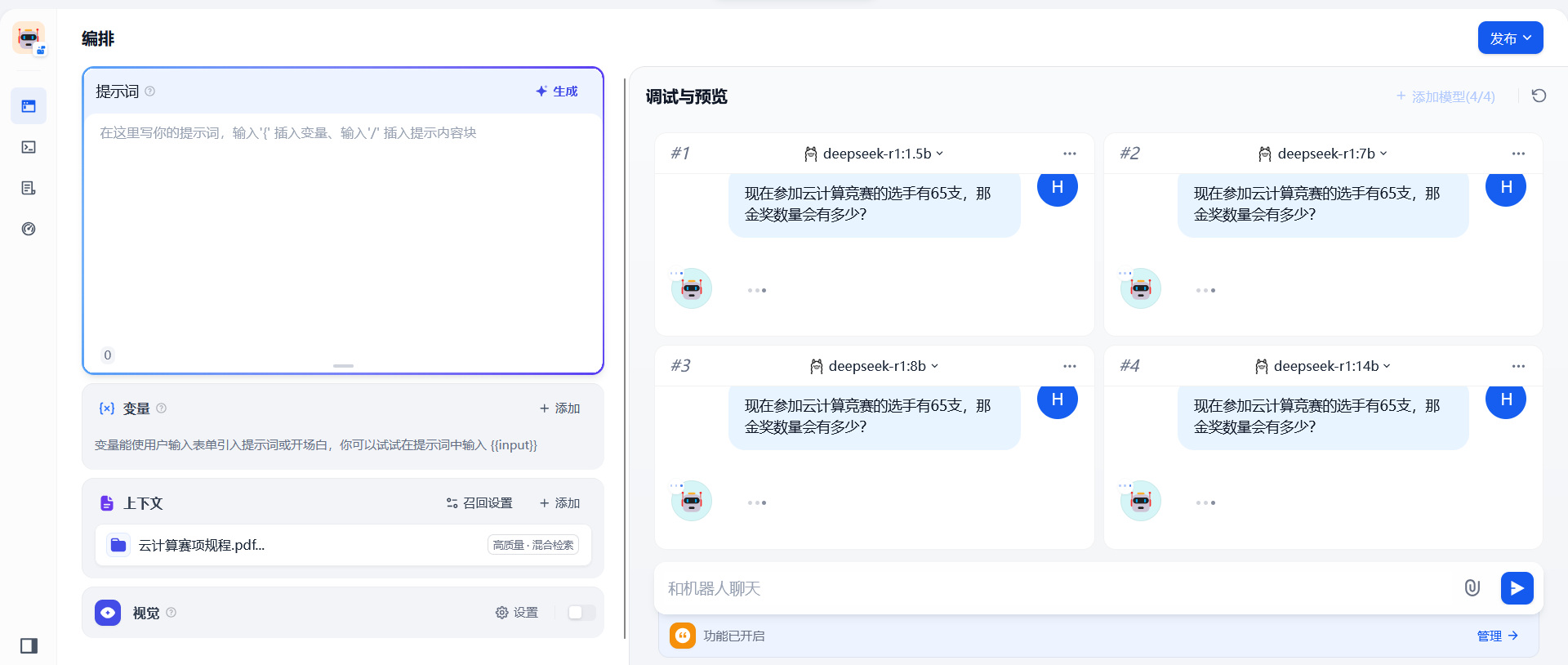
3:紧接着7b模型
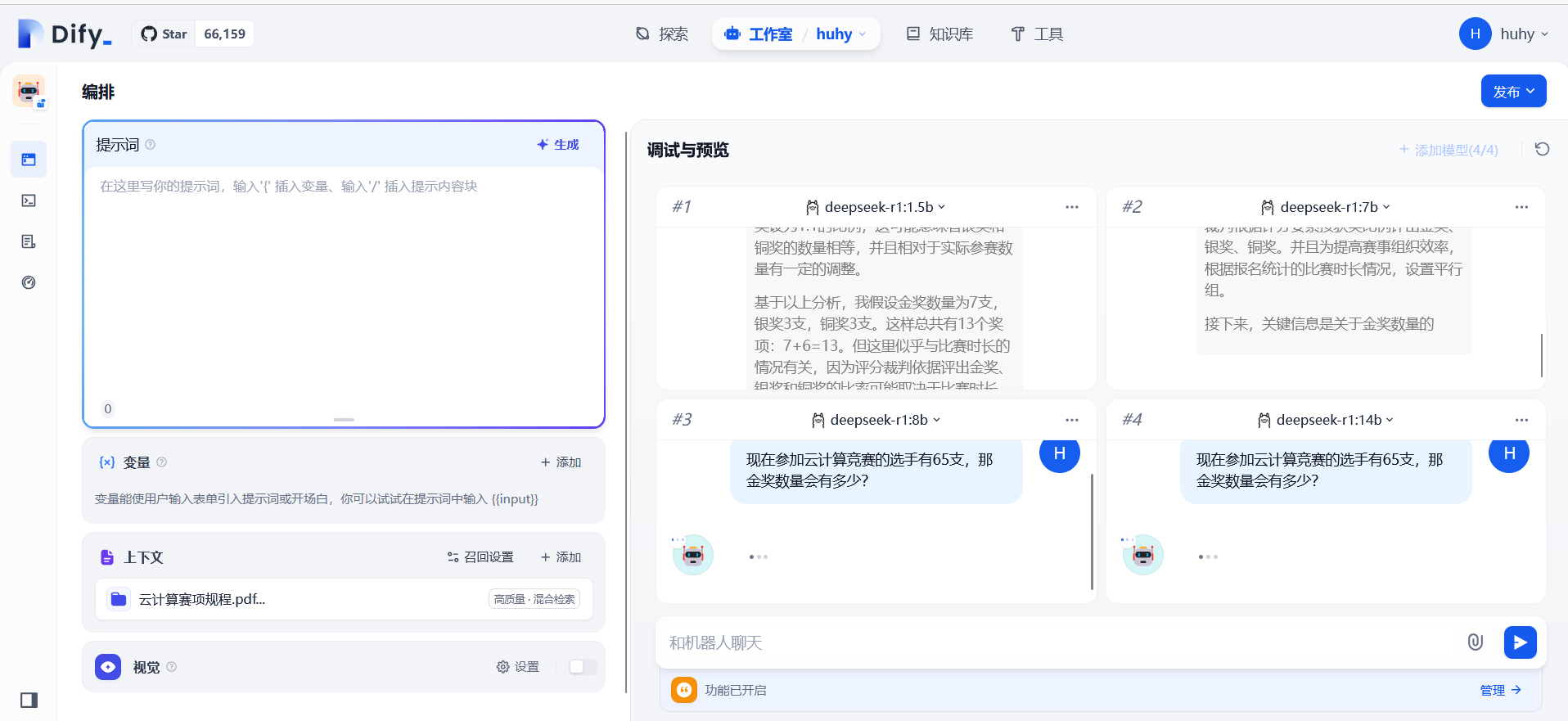
5:最后是14b模型
界面访问:http://IP:8080
用户名:admin 默认密码:MaxKB@123..
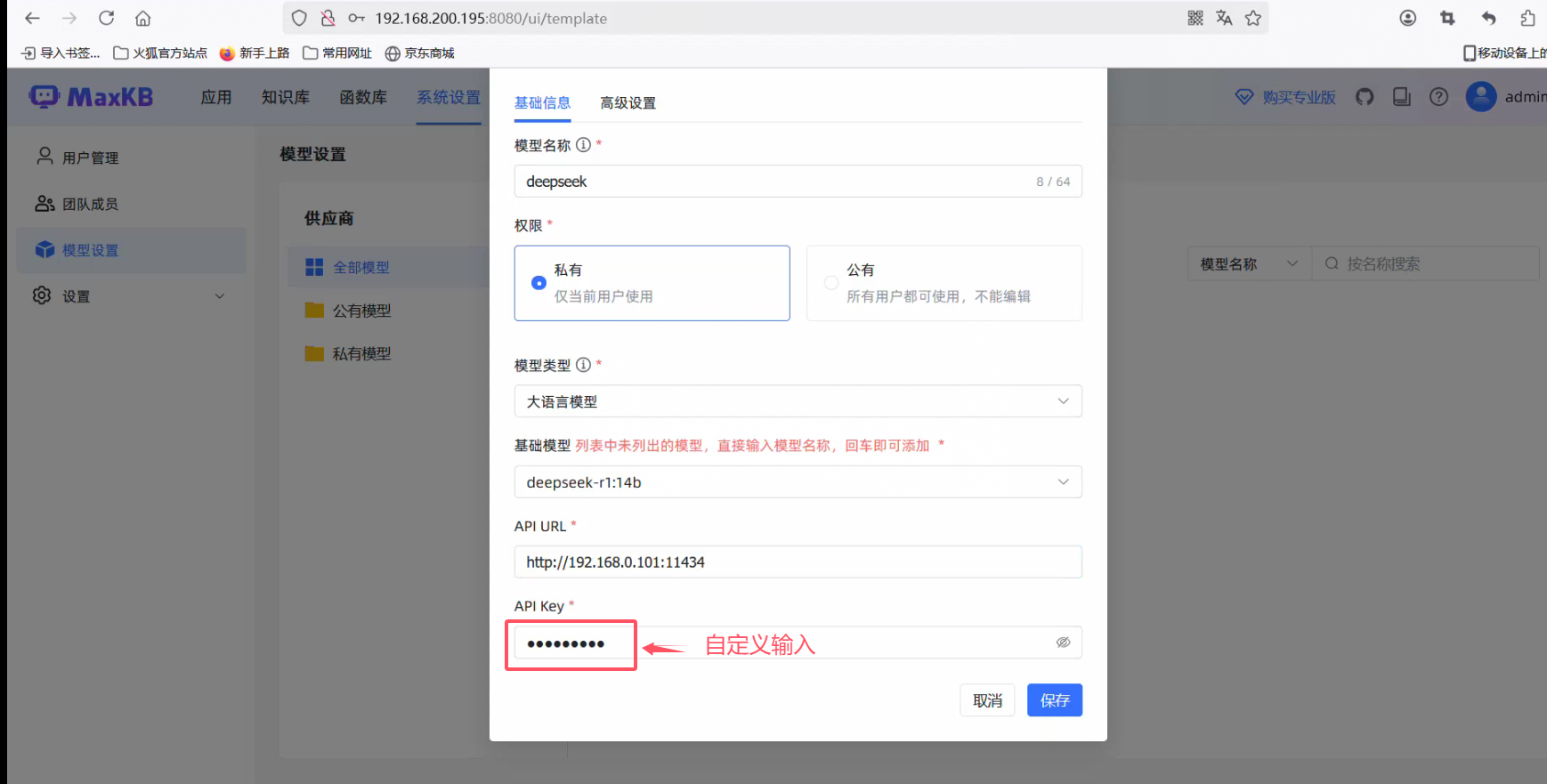
添加模型配置信息
配置本地知识库
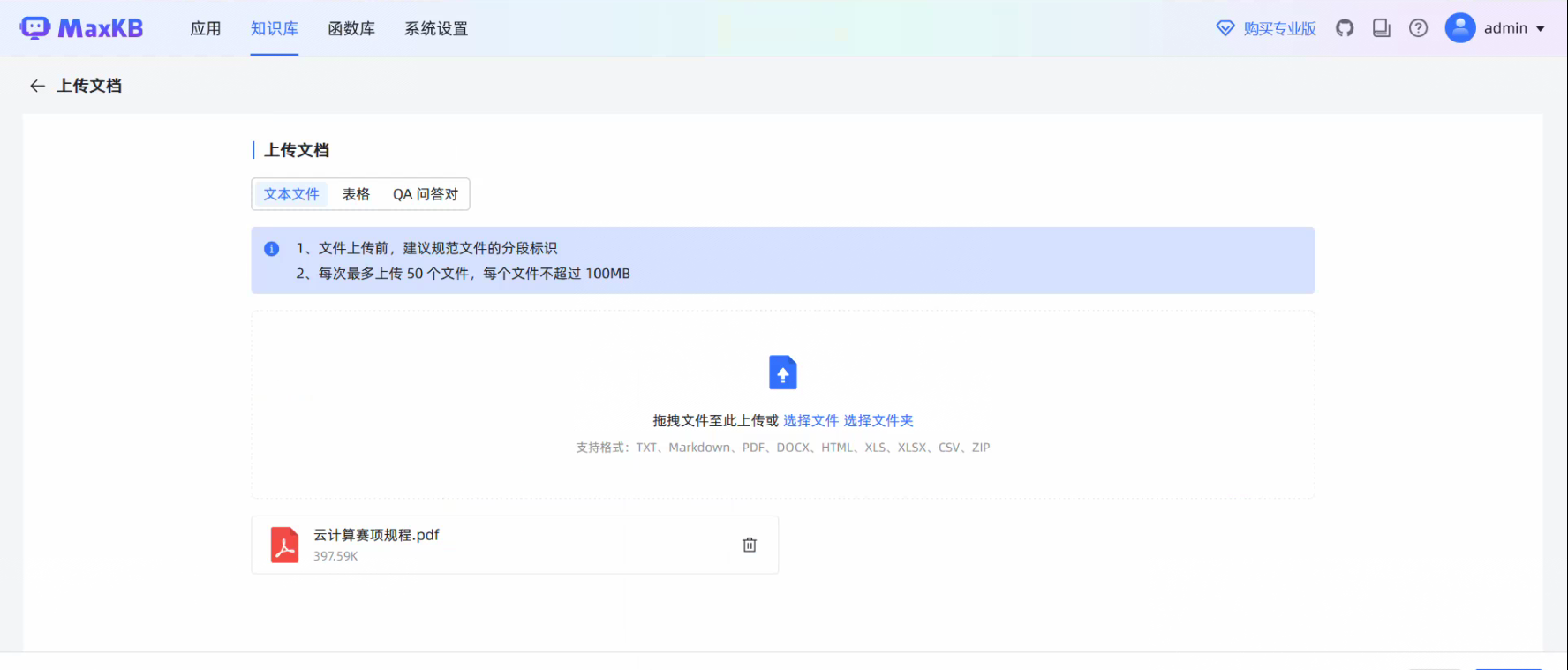
上传文件到知识库测试
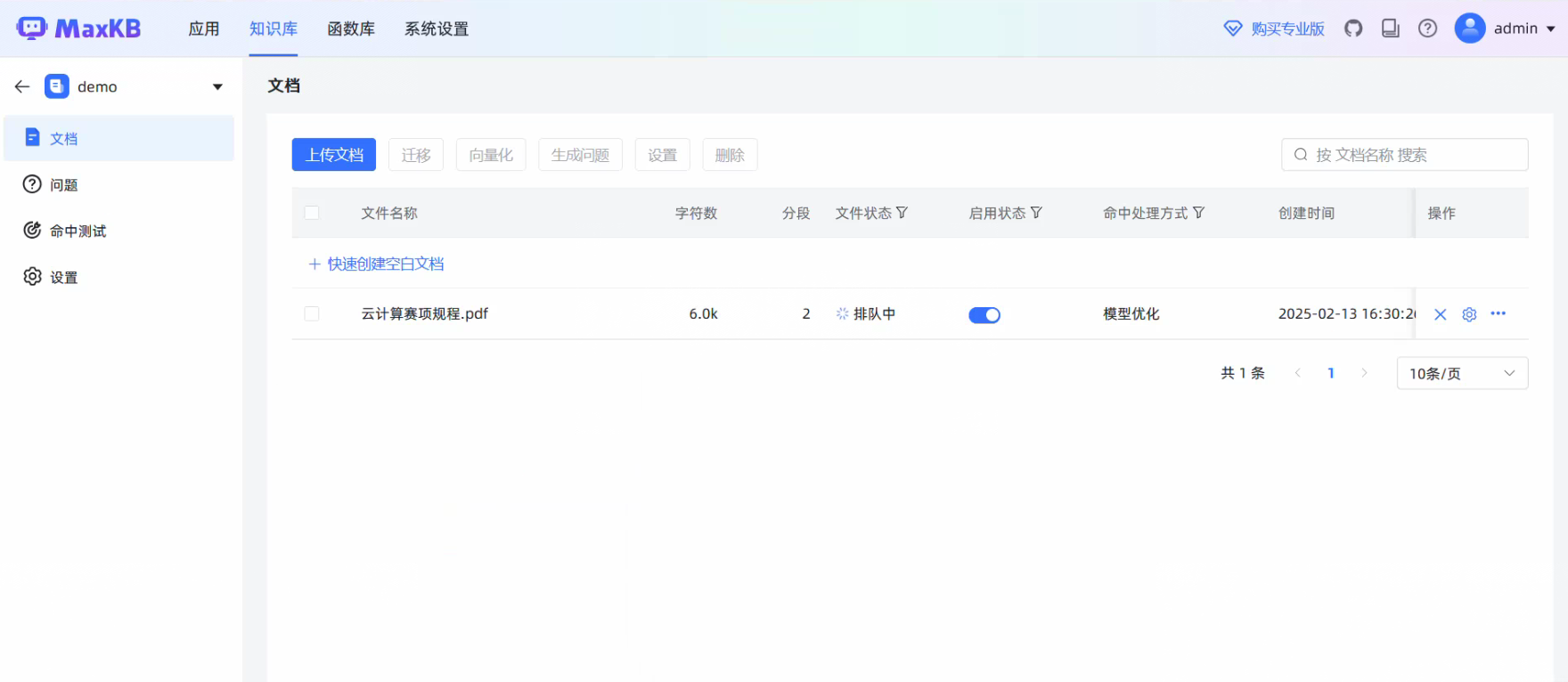
配置模型和知识库后即可聊天测试
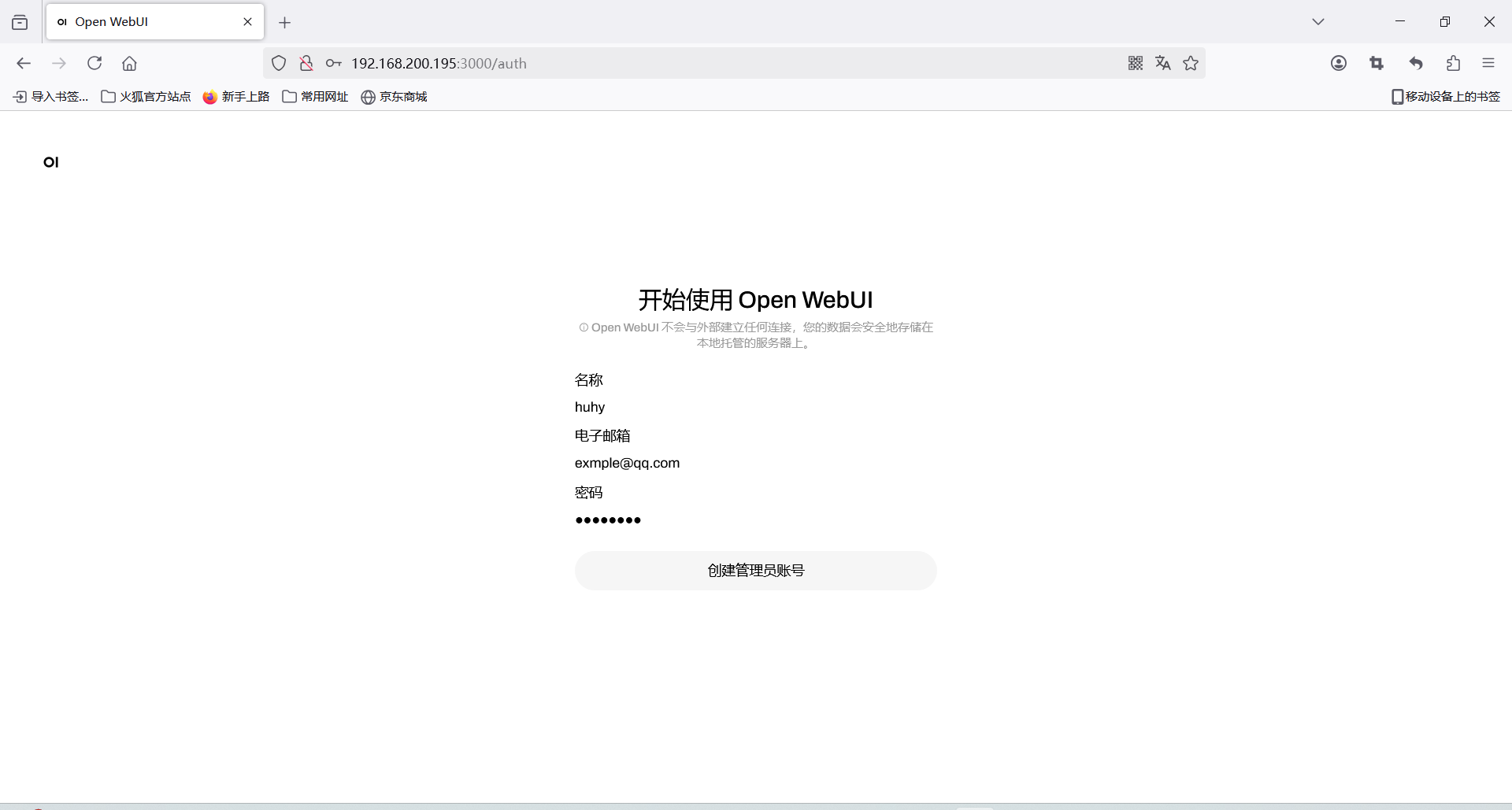
Docker安装Open-WebUi
GitHub官网
Open WebUI 是一个可扩展、功能丰富且用户友好的自托管 AI 平台,旨在完全离线运行。它支持各种 LLM 运行器(如Ollama)和与OpenAI 兼容的 API,并内置RAG 推理引擎,使其成为强大的 AI 部署解决方案。
使用默认配置进行安装
如果 Ollama 位于不同的服务器上,请使用以下命令:
如果计算机上有 Ollama,请使用以下命令:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
创建应用
使用默认的向量模型

登录后修改密码,添加模型
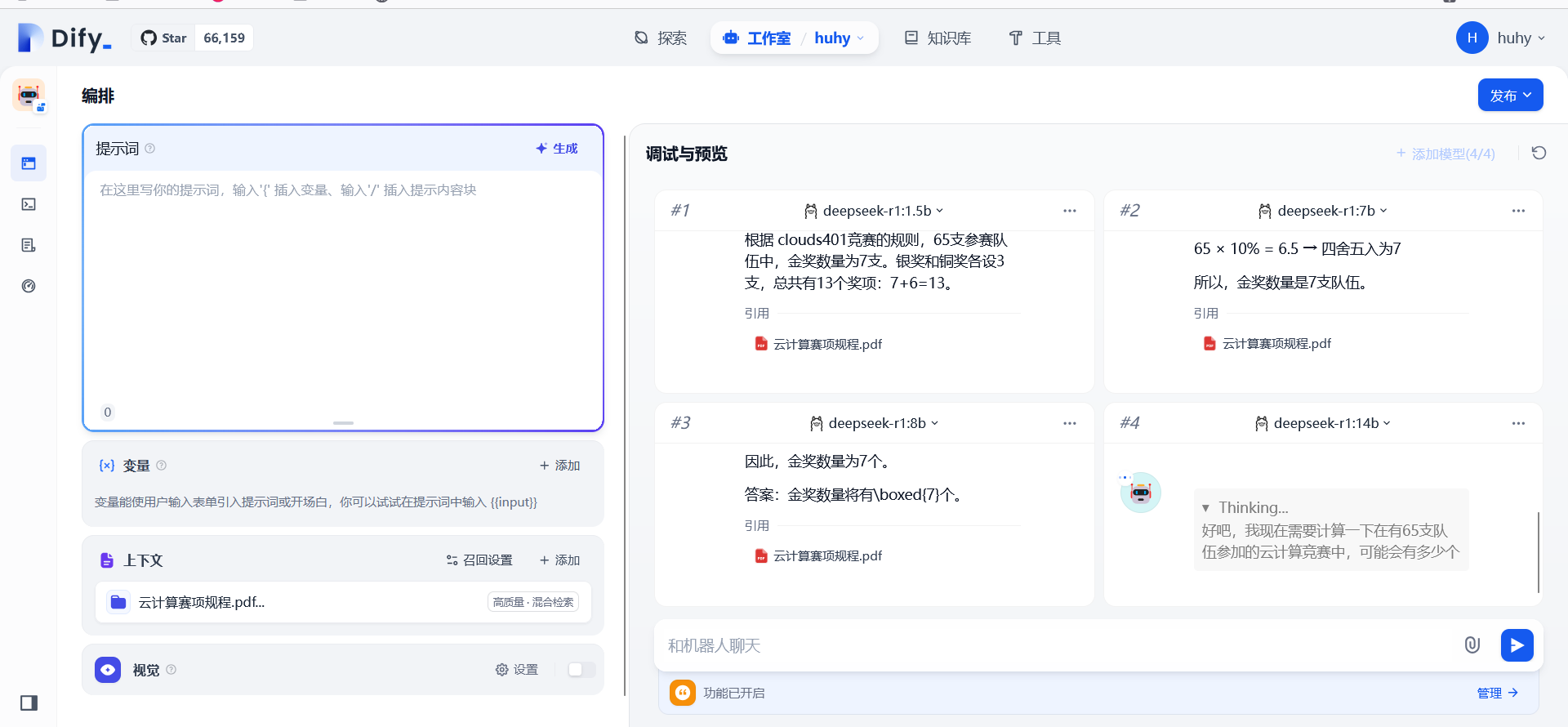
6:总体来说,模型越小速度越快,但思考深度方面相反
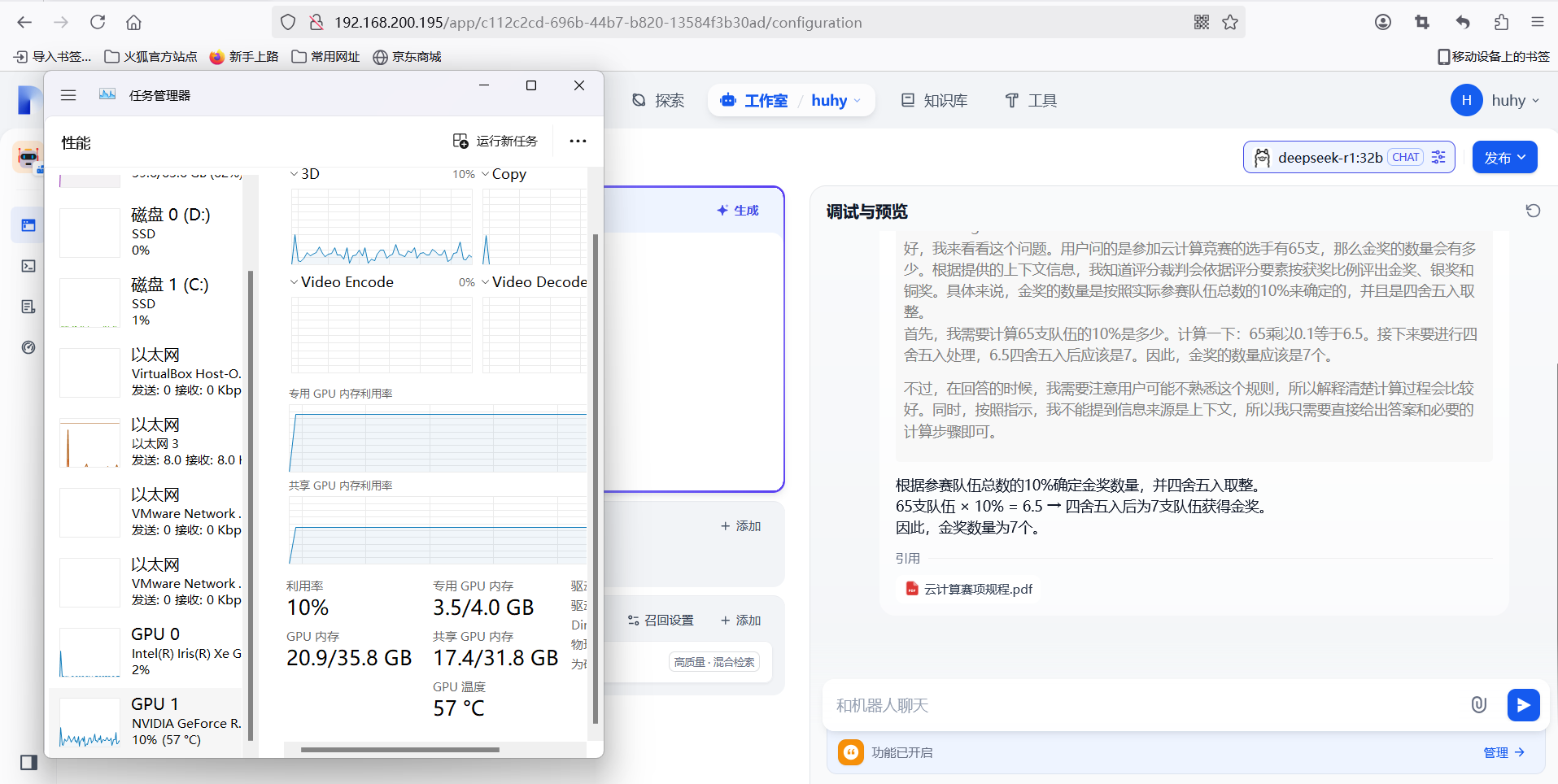
最后单独测试一下32b模型:显存肉眼可见的上升了,并且回答问题时十分卡顿,但相对来说回答的时候要更加考虑的全面一些
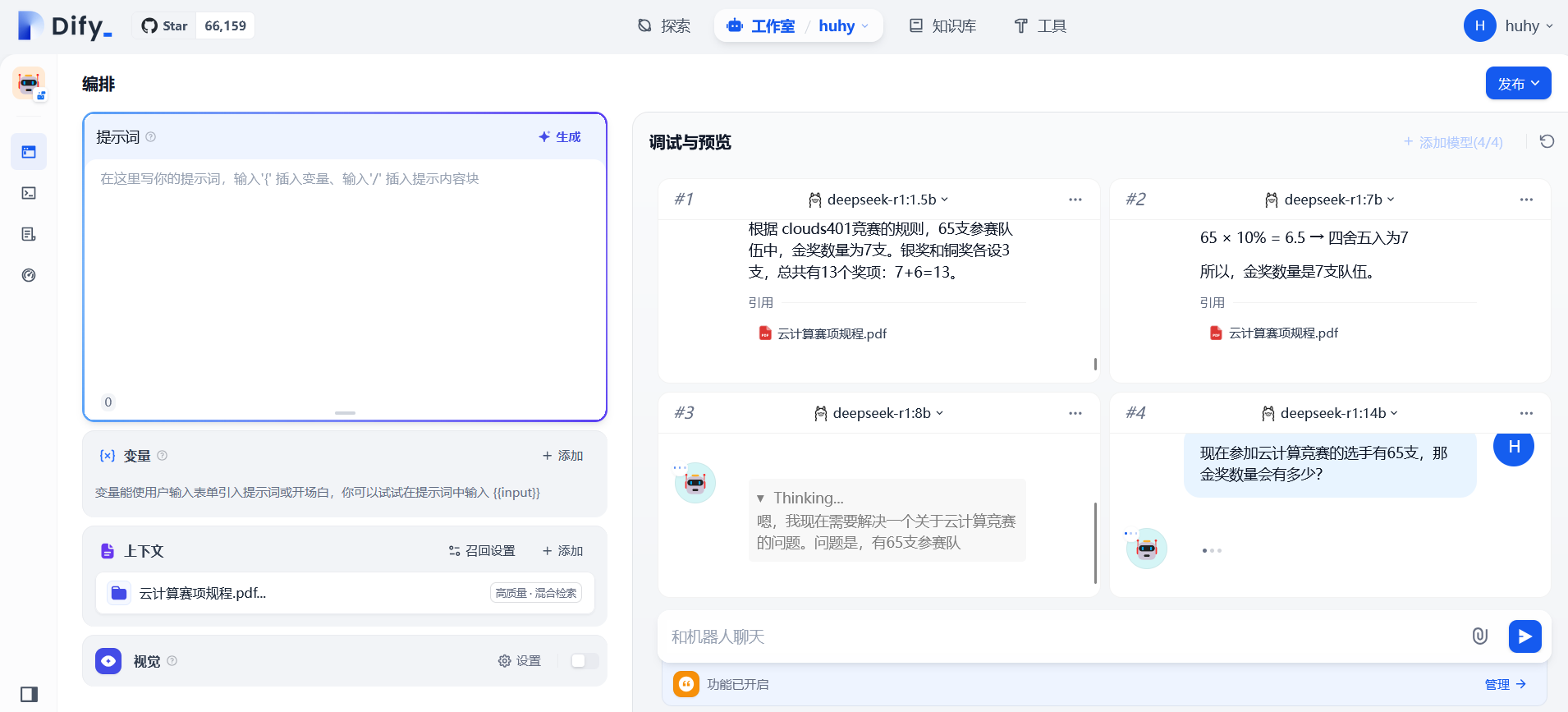
个人感觉还行:算是比较好用,就是需要多调试调试参数
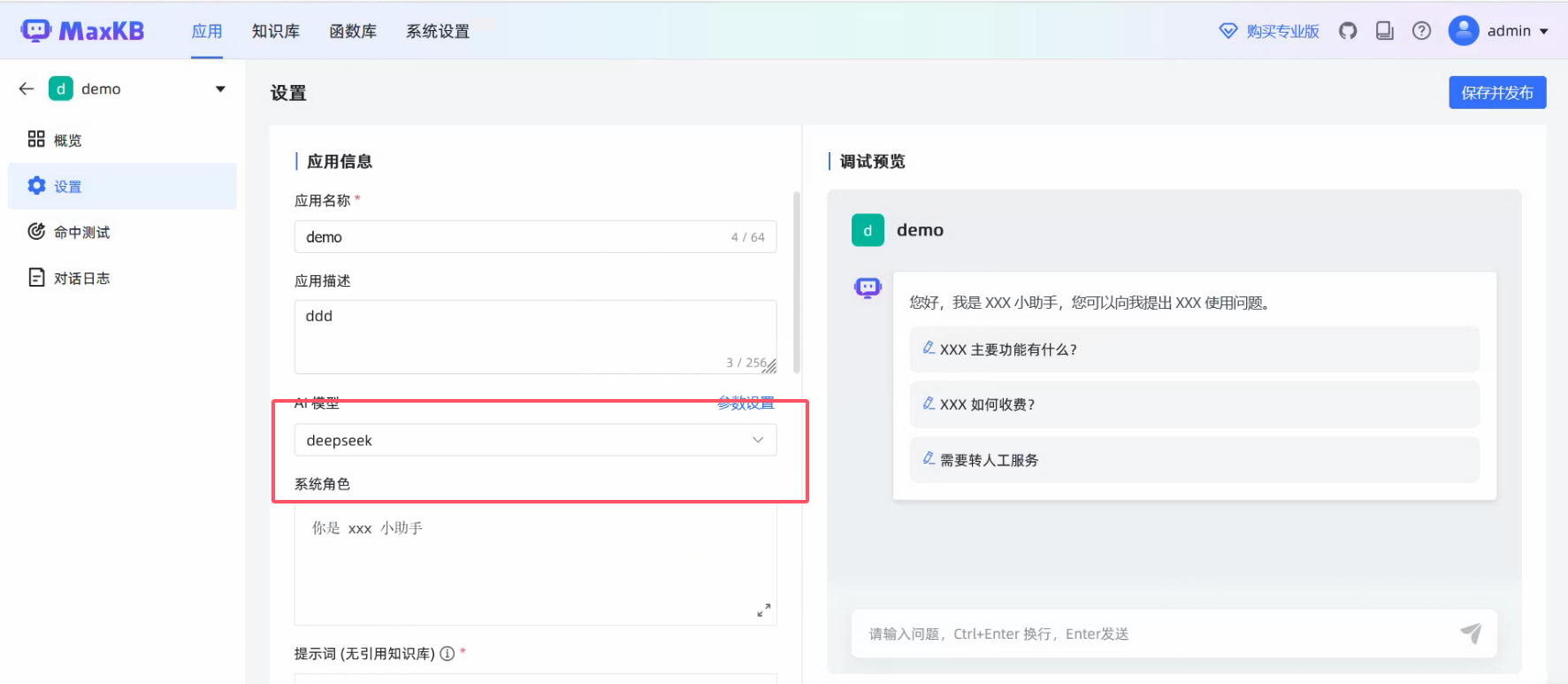
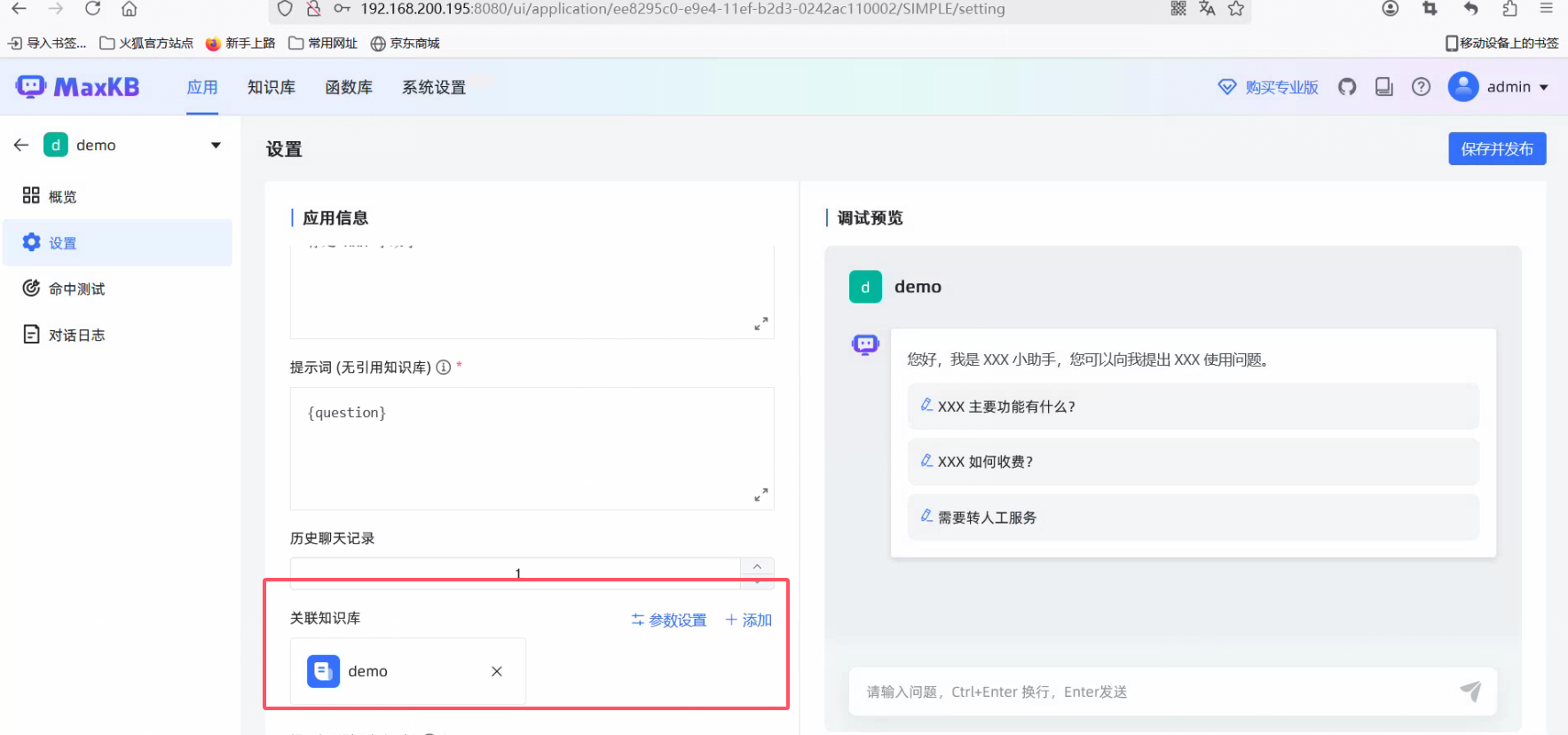
Docker安装MaxKb
官网
MaxKB = Max Knowledge Base,是一款基于大语言模型和 RAG 的开源知识库问答系统,广泛应用于智能客服、企业内部知识库、学术研究与教育等场景。
使用dcker进行安装:官网手册
docker run -d --name=maxkb --restart=always -p 8080:8080 -v ~/.maxkb:/var/lib/postgresql/data -v ~/.python-packages:/opt/maxkb/app/sandbox/python-packages registry.fit2cloud.com/maxkb/maxkb
root@huhy:~# docker run -d --name=maxkb --restart=always -p 8080:8080 -v ~/.maxkb:/var/lib/postgresql/data -v ~/.python-packages:/opt/maxkb/app/sandbox/python-packages registry.fit2cloud.com/maxkb/maxkb Unable to find image 'registry.fit2cloud.com/maxkb/maxkb:latest' locally latest: Pulling from maxkb/maxkb 55ab1b300d4b: Pull complete 516e670f76de: Pull complete c8202c7054c7: Pull complete 4493463449f8: Pull complete dcd6bd6b20be: Pull complete 8331472b7254: Pull complete 3dbb847e6011: Pull complete c5b148653b86: Pull complete cb92aacfeb80: Pull complete 41c71022e406: Pull complete 98fbd3f077e2: Pull complete cea15ef59043: Pull complete 9de9cd69634c: Pull complete 9c11f106b56c: Pull complete 3df6554d74e0: Pull complete 3409739a0deb: Pull complete dd4cc3ae0092: Pull complete fa6500045b27: Pull complete 6312008eda41: Pull complete ac40a96d9fc7: Pull complete 696f9213d112: Pull complete Digest: sha256:f922c66cd6c63179df4f2aaf320b89f28ef93101762b4953912ad272c9ca614a Status: Downloaded newer image for registry.fit2cloud.com/maxkb/maxkb:latest 7540ed7ecf668b2979e775a89a2a90760d781155a49ab13535e93c46cd631da4
4:1.5b(还计算了铜牌和银牌,但是有点问题)和7b模型都是回答准确,然后8b开始回答
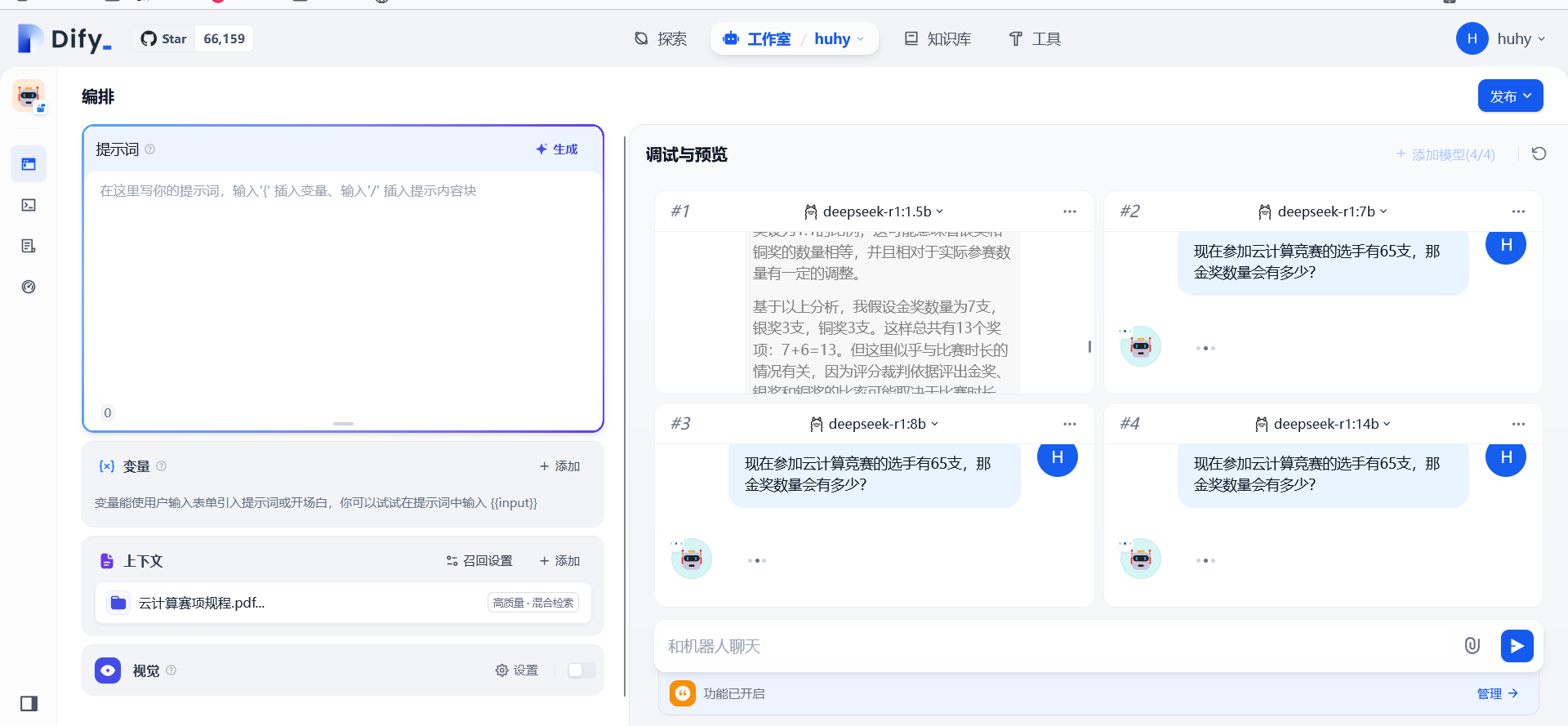
2:最小的1.5b模型先开始回答
要运行支持 Nvidia GPU 的 Open WebUI,请使用以下命令:
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda
安装后,可以通过http://localhost:3000访问 Open WebUI
如果仅使用 OpenAI API,请使用此命令:
docker run -d -p 3000:8080 -e OPENAI_API_KEY=your_secret_key -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
root@huhy:~# docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=http://192.168.0.101:11434 -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main Unable to find image 'ghcr.io/open-webui/open-webui:main' locally main: Pulling from open-webui/open-webui c29f5b76f736: Already exists 73c4bbda278d: Pull complete acc53c3e87ac: Pull complete ad3b14759e4f: Pull complete b874b4974f13: Pull complete 4f4fb700ef54: Pull complete dfcf69fcbc2b: Pull complete e8bfaf4ee0e0: Pull complete 17b8c991f4f9: Pull complete 17fcce97562b: Pull complete 2d116a8d53c4: Pull complete 59ab933b3f2f: Pull complete b3d65316b089: Pull complete 54fcedec75a0: Pull complete 5f8d44db0743: Pull complete Digest: sha256:26f0c76fcfe234ce6ad670fb65a9f772af0c263d261c2e2b3c784bae2d196c45 Status: Downloaded newer image for ghcr.io/open-webui/open-webui:main 44e56b1804e3cb1d279a9e7b965072c6f4939f5494163dccaa1e53ce2d81dfb3
创建管理员账户和密码
点击工作空间,找到知识库
登录后可直接使用模型,不需要配置连接Ollama
配置本地知识库
语言大模型(LLM, Large Language Model)
用于 文本生成、对话 AI、代码生成 等,如:GPT-4 OpenAI、DeepSeek、Qwen
适用领域:Chatbot、知识库问答、智能助手等
代码大模型(Code LLM)
用于 代码补全、自动编程,如:DeepSeek-Coder、CodeLlama、BigCode
适用领域:IDE 代码补全、AI 编程助手(如 Copilot)
多模态大模型(Multimodal LLM)
支持 文本 + 图像 + 语音 处理,如:Gemini、Qwen-VL、CogView
适用领域:图像理解、OCR 识别、智能创作(如 Midjourney)。
知识检索增强(RAG, Retrieval-Augmented Generation)
大模型结合知识库,如:LangChain、LlamaIndex
适用领域:智能客服、文档问答、搜索增强(如 ChatGPT+自有数据)。
大模型的训练方式
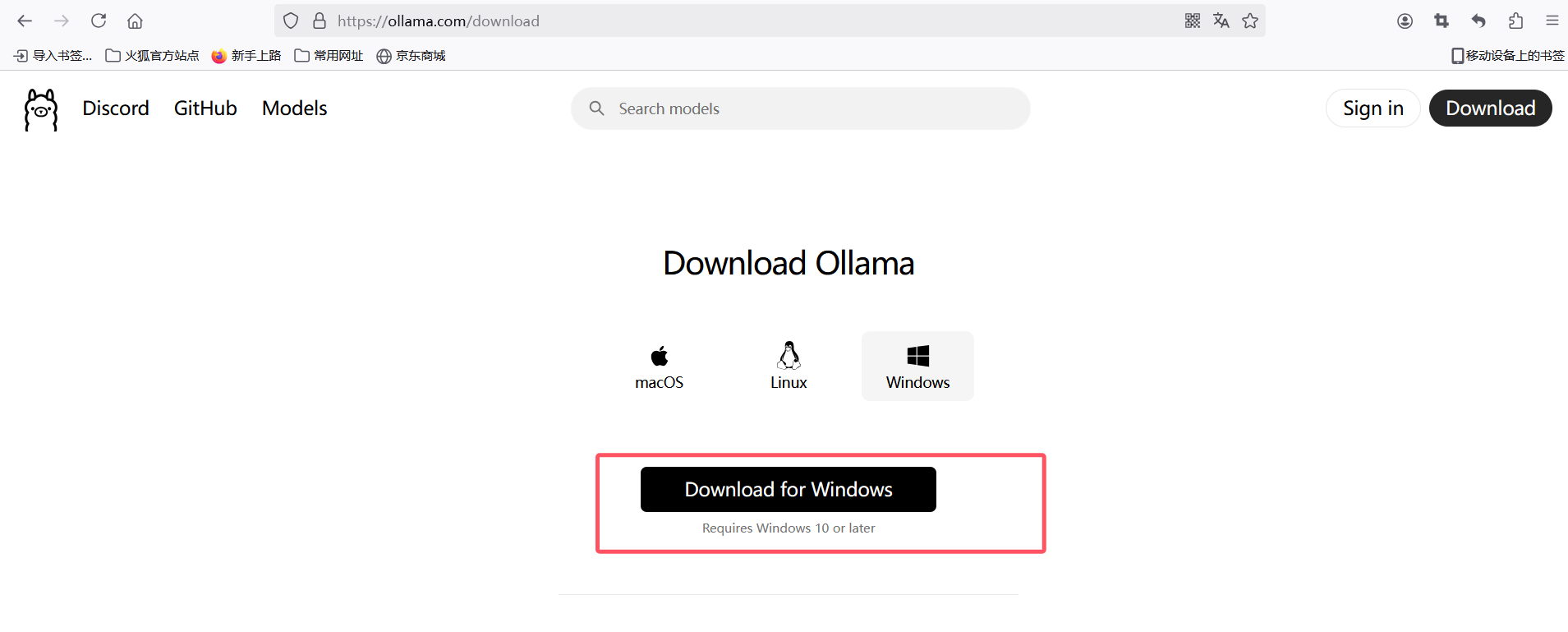
下载win版本即可
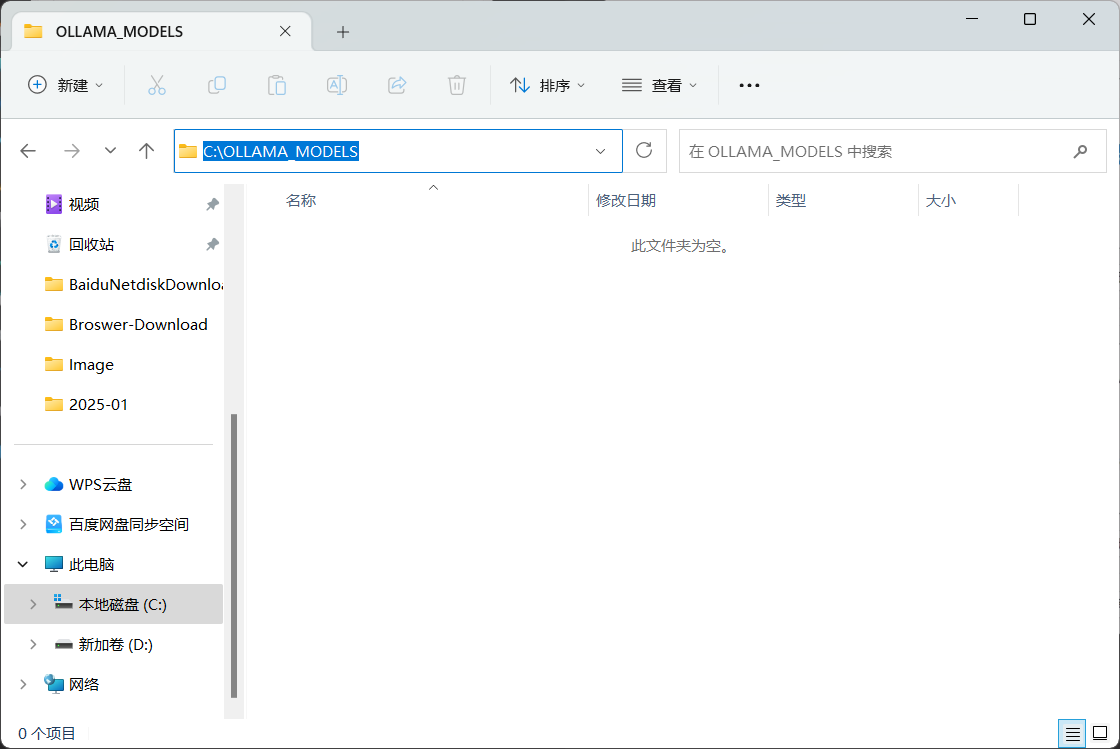
创建大模型下载目录并配置系统变量
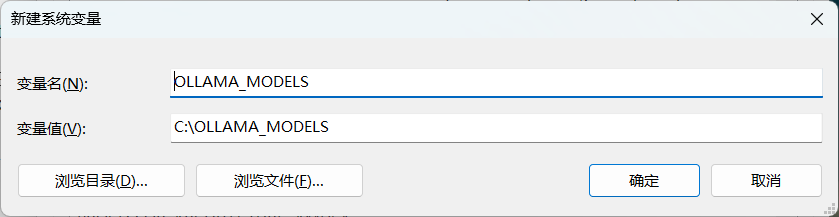
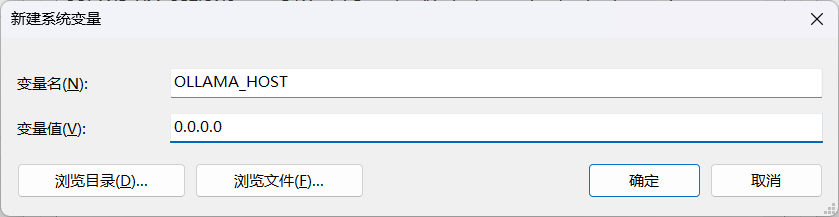
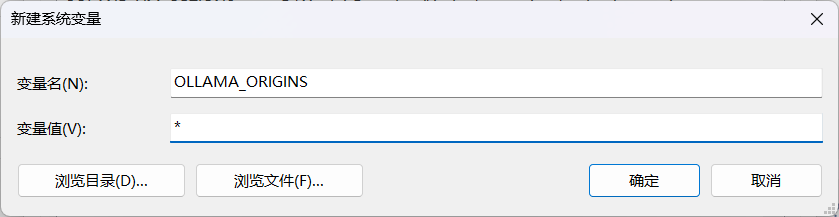
OLLAMA_HOST 0.0.0.0
OLLAMA_ORIGINS *
OLLAMA_MODELS C:\OLLAMA_MODELS(自定义模型保存位置,按照自身需求设置路径)
serve
打开powershell执行ollama能查看到命令即可
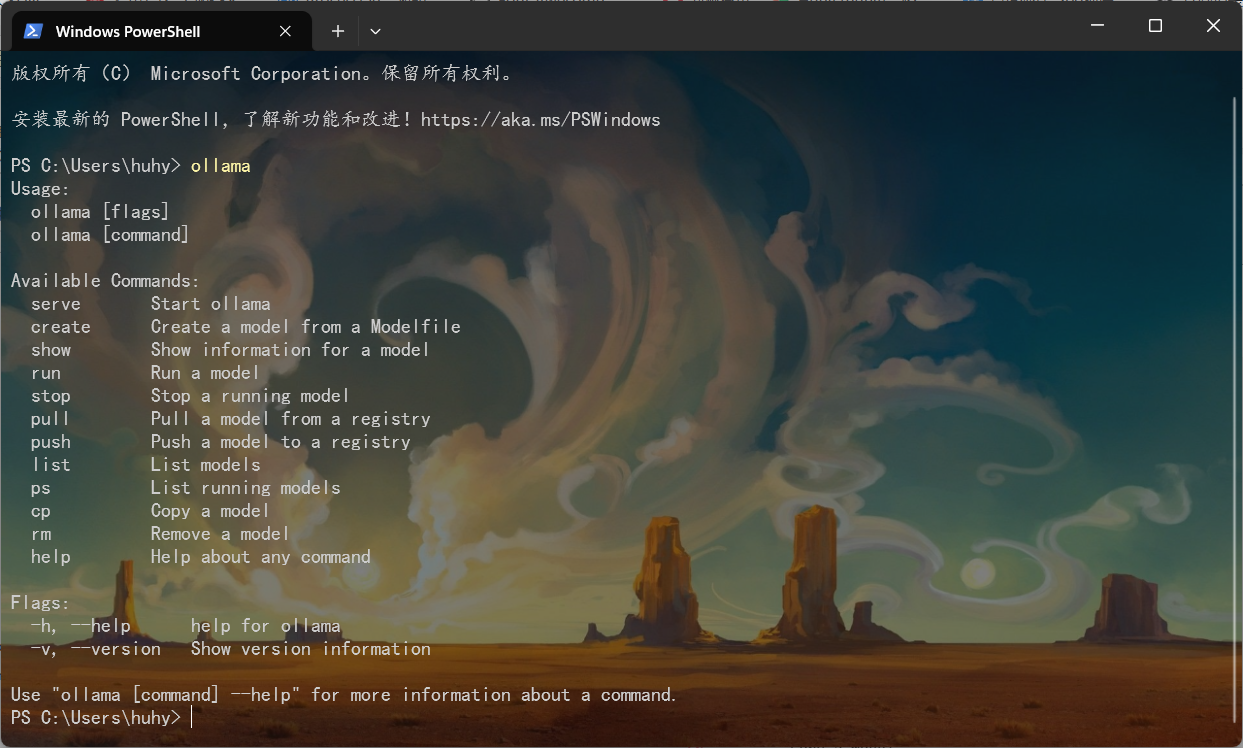
命令使用
下载后双击默认会安装在C盘
预训练(Pre-training):使用大量文本数据进行 自回归(Autoregressive) 或 自编码(Autoencoder) 训练。
指令微调(Instruction Tuning):对大模型进行 任务特定优化(如聊天、代码生成)。
RLHF(人类反馈强化学习):通过 人类评分 调整模型行为(如 ChatGPT 的训练)。
蒸馏(Distillation):将大模型知识压缩到小模型,提高推理速度(如 DeepSeek 1.5B 可能是 67B 的蒸馏版本)。
轻量级本地 LLM 运行工具(适合个人用户):适用于 Windows / Mac / Linux,零基础可用:
✅ Ollama(推荐 🌟)
特点:一键运行 LLM,支持 GGUF 量化,CLI & API 兼容 OpenAI
适用场景:轻量级 LLM 运行,本地聊天
支持模型:LLaMA, Mistral, DeepSeek, Qwen, Gemma
✅ LM Studio
特点:本地 GUI 可视化,支持 GGUF
适用场景:零基础使用,轻量聊天
支持模型:LLaMA, Mistral, DeepSeek
✅ GPT4All
特点:轻量级 GUI,本地 AI 聊天
适用场景:本地离线 AI 助手
支持模型:GPT4All, LLaMA, Mistral
安装Ollama
本实验主要使用win系统安装ollama部署deepseek-r1(1.5b、7b、8b、14b、32b等参数)并搭建对接市面上各个开源的WebUI工具和本地知识库
Ollama是一款跨平台推理框架客户端(MacOS、Windows、Linux),旨在无缝部署大型语言模型 (LLM),例如 Llama 2、Mistral、Llava 等。Ollama 的一键式设置支持 LLM 的本地执行,通过将数据保存在自己的机器上,提供增强的数据隐私和安全性。
使用win系统安装
官网
create
show
显示特定模型的信息,如版本、参数等
用法示例:
ollama show my-model
run
stop
pull
push
list
ps
cp
rm
对于多行输入,可以使用以下方式换行"“”:
用法示例:
>>> """Hello, ... world! ... """ I'm a basic program that prints the famous "Hello, world!" message to the console.
使用sh脚本安装
系统Ubuntu2404:注意需要配置显卡,不然只能跑内存
root@huhy:~# curl -fsSL https://ollama.com/install.sh | sh >>> Cleaning up old version at /usr/local/lib/ollama >>> Installing ollama to /usr/local >>> Downloading Linux amd64 bundle ######################################################################## 100.0% >>> Creating ollama user... >>> Adding ollama user to render group... >>> Adding ollama user to video group... >>> Adding current user to ollama group... >>> Creating ollama systemd service... >>> Enabling and starting ollama service... Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service. >>> The Ollama API is now available at 127.0.0.1:11434. >>> Install complete. Run "ollama" from the command line. WARNING: No NVIDIA/AMD GPU detected. Ollama will run in CPU-only mode.
root@huhy:~# systemctl status ollama ● ollama.service - Ollama Service Loaded: loaded (/etc/systemd/system/ollama.service; enabled; preset: enabled) Active: active (running) since Tue 2025-02-11 07:28:07 UTC; 2min 29s ago Main PID: 4219 (ollama) Tasks: 9 (limit: 4556) Memory: 30.4M (peak: 30.6M) CPU: 88ms CGroup: /system.slice/ollama.service └─4219 /usr/local/bin/ollama serve Feb 11 07:28:07 huhy ollama[4219]: [GIN-debug] GET /api/tags --> github.com/ollama/ollama/server.(*S> Feb 11 07:28:07 huhy ollama[4219]: [GIN-debug] GET /api/version --> github.com/ollama/ollama/server.(*S> Feb 11 07:28:07 huhy ollama[4219]: [GIN-debug] HEAD / --> github.com/ollama/ollama/server.(*S> Feb 11 07:28:07 huhy ollama[4219]: [GIN-debug] HEAD /api/tags --> github.com/ollama/ollama/server.(*S> Feb 11 07:28:07 huhy ollama[4219]: [GIN-debug] HEAD /api/version --> github.com/ollama/ollama/server.(*S> Feb 11 07:28:07 huhy ollama[4219]: time=2025-02-11T07:28:07.851Z level=INFO source=routes.go:1238 msg="Listening on 127> Feb 11 07:28:07 huhy ollama[4219]: time=2025-02-11T07:28:07.853Z level=INFO source=routes.go:1267 msg="Dynamic LLM libr> Feb 11 07:28:07 huhy ollama[4219]: time=2025-02-11T07:28:07.856Z level=INFO source=gpu.go:226 msg="looking for compatib> Feb 11 07:28:07 huhy ollama[4219]: time=2025-02-11T07:28:07.861Z level=INFO source=gpu.go:392 msg="no compatible GPUs w> Feb 11 07:28:07 huhy ollama[4219]: time=2025-02-11T07:28:07.861Z level=INFO source=types.go:131 msg="inference compute
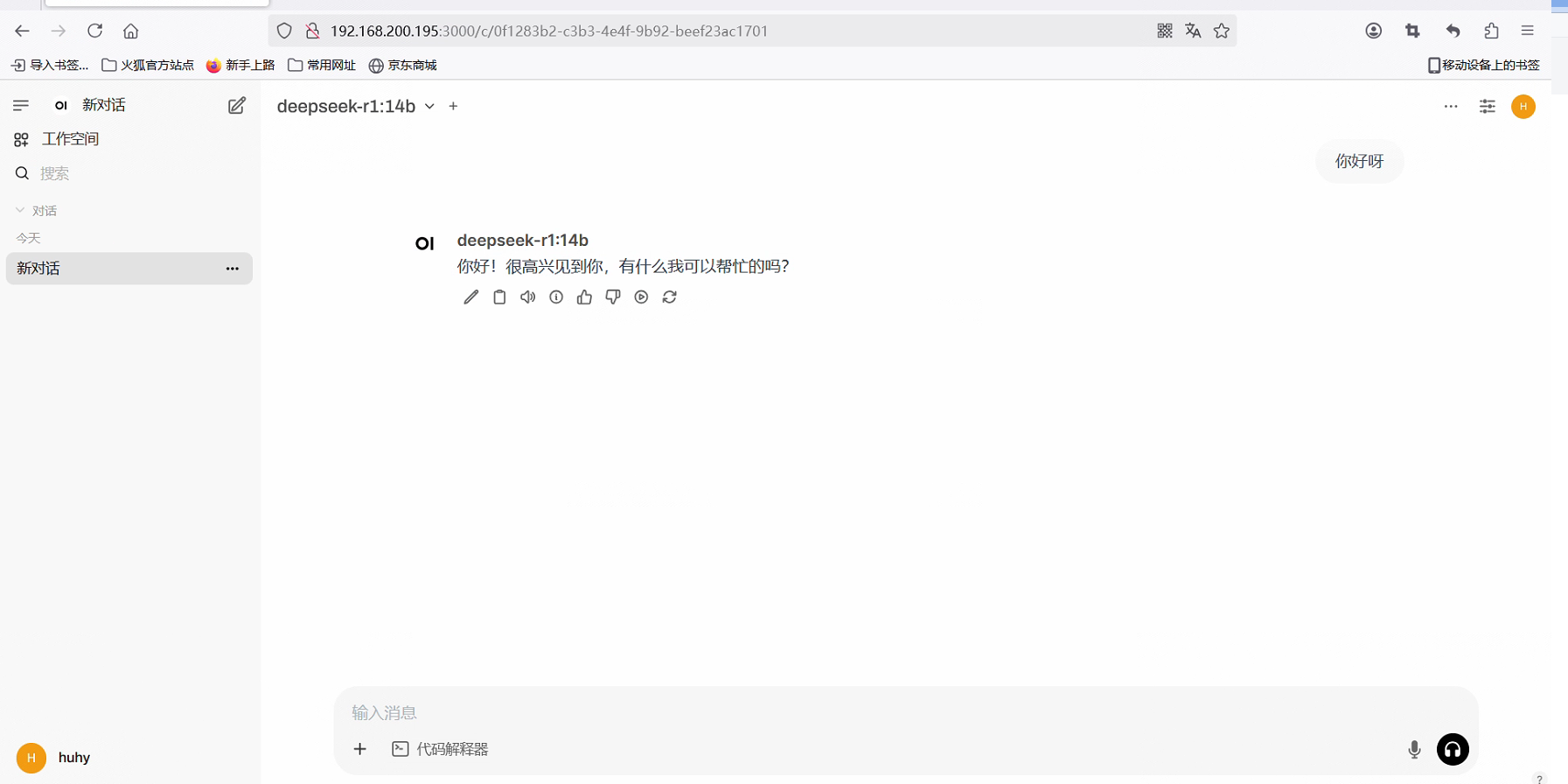
root@huhy:~# ollama run deepseek-r1:1.5b pulling manifest pulling aabd4debf0c8... 100% ▕██████████████████████████████████████████████████████████████████████████▏ 1.1 GB pulling 369ca498f347... 100% ▕██████████████████████████████████████████████████████████████████████████▏ 387 B pulling 6e4c38e1172f... 100% ▕██████████████████████████████████████████████████████████████████████████▏ 1.1 KB pulling f4d24e9138dd... 100% ▕██████████████████████████████████████████████████████████████████████████▏ 148 B pulling a85fe2a2e58e... 100% ▕██████████████████████████████████████████████████████████████████████████▏ 487 B verifying sha256 digest writing manifest success >>> Send a message (/? for h >>> 你好呀你好!很高兴见到你,有什么我可以帮忙的吗?😊
安装docker
apt -y install apt-transport-https ca-certificates curl software-properties-common curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add - add-apt-repository "deb [arch=amd64] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable" apt-get -y install docker-ce
配置生产存储库:使用 NVIDIA GPU 驱动程序
配置daemon文件
vi /etc/docker/daemon.json
{ "registry-mirrors": ["https://registry-mirrors.yunyuan.co"], "insecure-registries" : ["0.0.0.0/0"] }systemctl daemon-reload systemctl restart docker
配置监听地址
vim /etc/systemd/system/ollama.service
[Unit] Description=Ollama Service After=network-online.target [Service] ExecStart=/usr/local/bin/ollama serve User=ollama Group=ollama Restart=always RestartSec=3 #Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin" Environment="OLLAMA_HOST=0.0.0.0" # 将上面行注释,添加此行 [Install] WantedBy=default.target
systemctl daemon-reload systemctl restart ollama
root@huhy:~# ss -tlun | grep 11 tcp LISTEN 0 4096 *:11434 *:*
使用docker安装
系统Ubuntu2404:
可选)配置存储库以使用实验性软件包:
sed -i -e '/experimental/ s/^#//g' /etc/apt/sources.list.d/nvidia-container-toolkit.list
使用以下命令配置容器运行时nvidia-ctk:
安装 NVIDIA Container Toolkit 软件包:
apt update apt install -y nvidia-container-toolkit
配置docker:官网
要为以Rootless 模式运行的 Docker 配置容器运行时,请按照以下步骤操作:
重新启动 Rootless Docker 守护进程:
systemctl --user restart docker
启动容器
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
官网基本上支持市面的大部分模型:本实验以deepseek为例:
要使用带有 AMD GPU 的 Docker 运行 Ollama,请使用rocm标签和以下命令:
docker run -d --device /dev/kfd --device /dev/dri -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama:rocm
下载大模型
Ollama官网
电脑系统信息:
硬件信息 配置 操作系统 W11专业版 CPU 12th Gen Intel® Core™ i5-12500H 2.50 GHz RAM 64.0 GB 显卡 3050ti 显存 36.0 GB 官网说明:至少有 8 GB 的 RAM 来运行 7B 型号,16 GB 的 RAM 来运行 13B 型号,32 GB 的 RAM 来运行 33B 型号
/etc/nvidia-container-runtime/config.toml使用以下命令进行配置:sudo nvidia-ctk
nvidia-ctk config --set nvidia-container-cli.no-cgroups --in-place
下载模型:命令格式如下(注意大多时候下载模型可能会报错,受网络影响,一般早上下载比较好,多试几次反复尝试!)
ollama run deepseek-r1:模型参数
PS C:\Users\huhy> ollama run deepseek-r1:1.5b pulling manifest pulling aabd4debf0c8... 100% ▕████████████████████████████████████████████████████████▏ 1.1 GB pulling 369ca498f347... 100% ▕████████████████████████████████████████████████████████▏ 387 B pulling 6e4c38e1172f... 100% ▕████████████████████████████████████████████████████████▏ 1.1 KB pulling f4d24e9138dd... 100% ▕████████████████████████████████████████████████████████▏ 148 B pulling a85fe2a2e58e... 100% ▕████████████████████████████████████████████████████████▏ 487 B verifying sha256 digest writing manifest success
PS C:\Users\huhy> ollama list NAME ID SIZE MODIFIED deepseek-r1:32b 38056bbcbb2d 19 GB 45 seconds ago deepseek-r1:14b ea35dfe18182 9.0 GB 2 hours ago deepseek-r1:8b 28f8fd6cdc67 4.9 GB 2 hours ago deepseek-r1:7b 0a8c26691023 4.7 GB 2 hours ago deepseek-r1:1.5b a42b25d8c10a 1.1 GB 2 hours ago
()从 GGUF 导入
Huggingface官方下载
GGUF(GPT-Generated Unified Format)是一种专门为大型语言模型设计的文件格式,旨在优化模型的存储、加载和推理效率。它通常用于本地部署的模型(如基于LLaMA、Falcon等架构的模型),尤其是在资源受限的设备上(如个人电脑或嵌入式设备)
GGUF模型的核心特点
使用docker compose 启动Dify,使用Ubuntu2404系统安装docker和docker compose
apt -y install apt-transport-https ca-certificates curl software-properties-common curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add - add-apt-repository "deb [arch=amd64] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable" apt-get -y install docker-ce
下载Dify文件
前端界面访问:可以通过浏览器通过http://localhost/install访问 Dify 仪表板并开始初始化过程
输入密码登录
上传后解压
apt install -y unzip
unzip dify-main.zip
cd dify-main/ cd docker cp .env.example .env docker compose up -d
root@huhy:~/dify-main/docker# docker compose up -d [+] Running 74/74 ✔ sandbox Pulled 316.6s ✔ worker Pulled 284.7s ✔ weaviate Pulled 247.6s ✔ nginx Pulled12.3s ✔ api Pulled 284.7s ✔ web Pulled 241.4s ✔ db Pulled 112.2s ✔ redis Pulled 175.1s ✔ ssrf_proxy Pulled 85.7s [+] Running 11/11 ✔ Network docker_default Created 0.1s ✔ Network docker_ssrf_proxy_network Created 0.1s ✔ Container docker-sandbox-1 Started 1.7s ✔ Container docker-db-1 Started 1.7s ✔ Container docker-web-1 Started 1.8s ✔ Container docker-redis-1 Started 2.0s ✔ Container docker-ssrf_proxy-1 Started 1.9s ✔ Container docker-weaviate-1 Started 1.8s ✔ Container docker-worker-1 Started 3.2s ✔ Container docker-api-1 Started 3.2s ✔ Container docker-nginx-1 Started 4.0s root@huhy:~/dify-main/docker# docker compose ps NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS docker-api-1 langgenius/dify-api:0.15.3 "/bin/bash /entrypoi…" api 14 seconds ago Up 12 seconds 5001/tcp docker-db-1 postgres:15-alpine "docker-entrypoint.s…" db 15 seconds ago Up 14 seconds (healthy) 5432/tcp docker-nginx-1 nginx:latest "sh -c 'cp /docker-e…" nginx 14 seconds ago Up 11 seconds 0.0.0.0:80->80/tcp, :::80->80/tcp, 0.0.0.0:443->443/tcp, :::443->443/tcp docker-redis-1 redis:6-alpine "docker-entrypoint.s…" redis 15 seconds ago Up 13 seconds (health: starting) 6379/tcp docker-sandbox-1 langgenius/dify-sandbox:0.2.10 "/main" sandbox 15 seconds ago Up 14 seconds (health: starting) docker-ssrf_proxy-1 ubuntu/squid:latest "sh -c 'cp /docker-e…" ssrf_proxy 15 seconds ago Up 13 seconds 3128/tcp docker-weaviate-1 semitechnologies/weaviate:1.19.0 "/bin/weaviate --hos…" weaviate 15 seconds ago Up 14 seconds docker-web-1 langgenius/dify-web:0.15.3 "/bin/sh ./entrypoin…" web 15 seconds ago Up 14 seconds 3000/tcp docker-worker-1 langgenius/dify-api:0.15.3 "/bin/bash /entrypoi…" worker 14 seconds ago Up 12 seconds 5001/tcp root@huhy:~/dify-main/docker#
配置daemon
cat > /etc/docker/daemon.json
高效存储
GGUF采用量化技术(如4-bit、8-bit量化),大幅减少模型文件大小,同时尽量保持模型性能。
适合在本地设备上存储和运行,尤其是显存或内存有限的场景。
快速加载
GGUF格式针对加载速度进行了优化,能够更快地将模型加载到内存或显存中,减少启动延迟。
跨平台兼容
GGUF格式设计时考虑了跨平台支持,可以在不同操作系统(如Windows、Linux、macOS)和设备(如CPU、GPU)上运行。
模块化设计
GGUF支持将模型拆分为多个文件,便于分块加载或更新,特别适合大型模型。
易于部署
GGUF格式通常与开源推理框架(如llama.cpp)配合使用,能够简化模型的本地部署流程。
创建一个名为 的文件Modelfile,其中FROM包含要导入的模型的本地文件路径的指令。(注意makefile文件和gguf文件要在同一目录)
FROM ./vicuna-33b.Q4_0.gguf
在 Ollama 中创建模型
ollama create example -f Modelfile
运行模型
ollama run example
搭建WebUI工具和本地知识库
WebUI 工具用于可视化界面进行AI对话,有不少是自带知识库(RAG,Retrieval-Augmented Generation),适用于本地私有知识库、企业内网、个人 AI 助手。例如:
工具 特点 开源 适用场景 Dify 🌟 可视化 AI 助手,低代码构建,支持 RAG ✅ 企业知识库,AI 应用开发 MaxKB 🌟 轻量级本地知识库,支持多格式文档 ✅ 本地 RAG 知识库 OpenWebUI ChatGPT 风格 UI,集成知识库 ✅ 个人 AI 助手,知识库问答 AnythingLLM 一体化AI 应用程序 ✅ 零设置、私有、一体化的 AI 程序,本地 LLM、RAG 和 AI 代理 FastGPT 可视化 RAG,支持 SQL 知识库 ✅ 企业内部搜索,数据分析 LangChain WebUI 可视化 RAG 工作流,集成多数据库 ✅ 知识库工作流,企业内部工具 Chatbot UI + LlamaIndex 结合 LlamaIndex 实现知识库问答 ✅ 高级用户,自定义 RAG Haystack NLP 框架,支持 RAG + 文档搜索 ✅ 企业知识库,问答系统 Docker安装Dify
GitHub官网
Dify 是一个开源 LLM 应用开发平台。其直观的界面结合了代理 AI 工作流、RAG 管道、代理功能、模型管理、可观察性功能等,让您可以快速从原型转向生产
大模型的核心特点
✅ 超大规模参数:从 数十亿(Billion)到万亿(Trillion)级别参数,比如 GPT-4、Gemini、DeepSeek、Qwen、ChatGLM 等。
✅ 基于 Transformer 架构:大多数大模型使用 Transformer 作为基础(如 GPT, LLaMA, Mistral, Baichuan 等)。
✅ 支持多任务处理:可以进行 文本理解、摘要、代码生成、图像识别(多模态)等。
✅ 可微调(Fine-tuning):可以通过 LoRA、QLoRA、P-tuning 等技术针对特定领域优化。
✅ 可本地部署或云端 API 访问:如 OpenAI 的 GPT-4 需 API 调用,而 LLaMA、DeepSeek 可本地运行。
大模型的主要类型
大模型可以按照应用方向划分为以下几类:
启动 Ollama 服务器,使其处于运行状态,等待处理请求
用法示例:
ollama serve
从 Modelfile 创建一个新的模型
用法示例:
ollama create my-model
运行一个模型,通常用于推理任务(如聊天、生成文本等)
用法示例:
ollama run my-model
停止正在运行的模型。
用法示例:
ollama stop my-model
从注册表(服务器)拉取一个模型到本地
用法示例:
ollama pull my-model
将本地模型推送到注册表(服务器)
用法示例:
ollama push my-model
列出本地可用的模型
用法示例:
ollama list
列出当前正在运行的模型。
用法示例:
ollama ps
复制一个模型。
用法示例:
ollama cp my-model new-model
删除本地的一个模型。
用法示例:
ollama rm my-model
官网
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
该nvidia-ctk命令会修改/etc/docker/daemon.json主机上的文件。文件已更新,以便 Docker 可以使用 NVIDIA 容器运行时
nvidia-ctk runtime configure --runtime=docker
systemctl daemon-reload systemctl restart docker
模式
使用以下命令配置容器运行时nvidia-ctk:
nvidia-ctk runtime configure --runtime=docker --config=$HOME/.config/docker/daemon.json
对应模型参数所需磁盘空间如下:我的建议是磁盘空间允许的话可以都下载试试,根据自己电脑的实际情况来进行判断那个模型参数更适合自己电脑
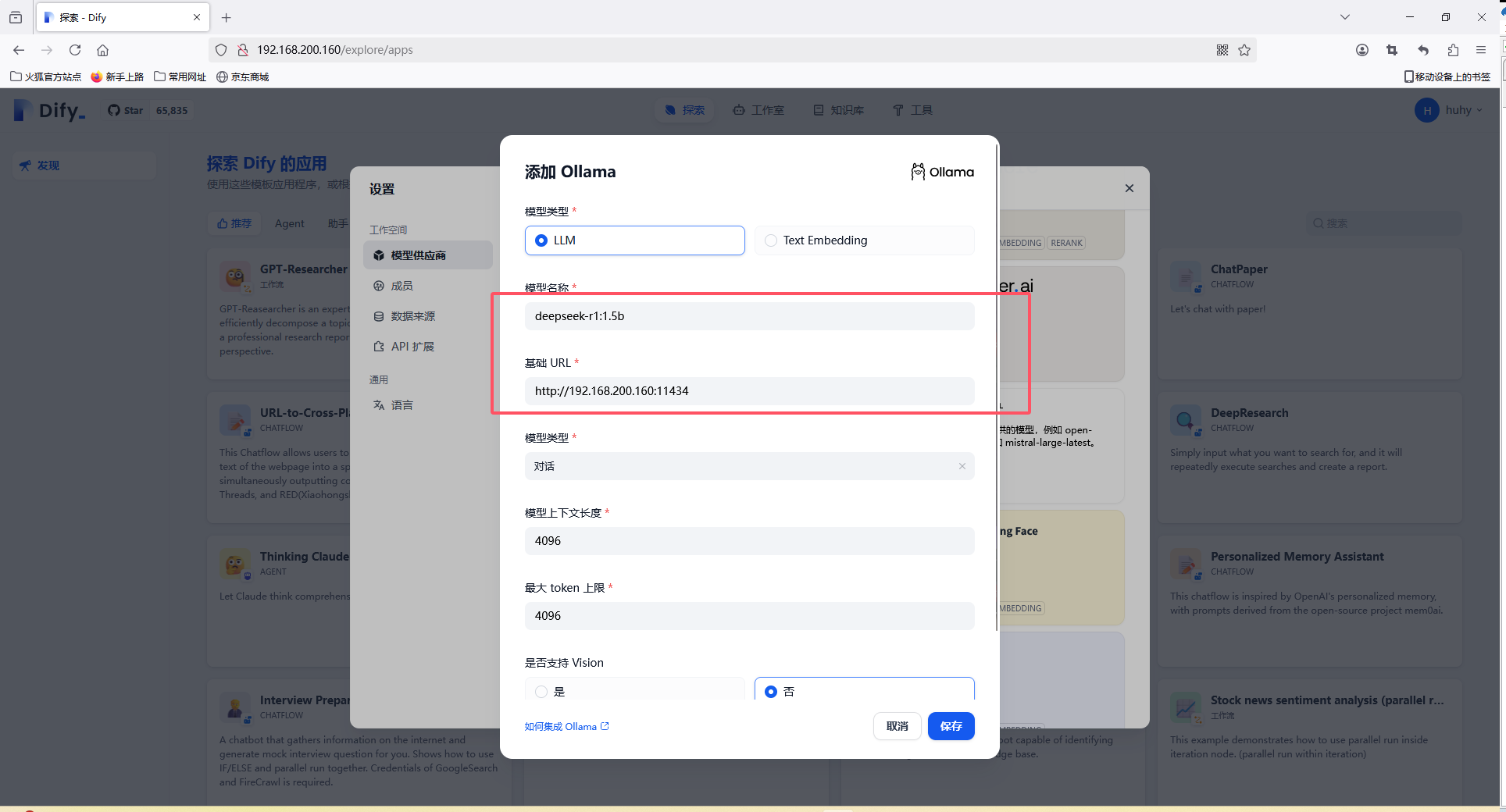
右上角账号中找到设置,选择模型供应商
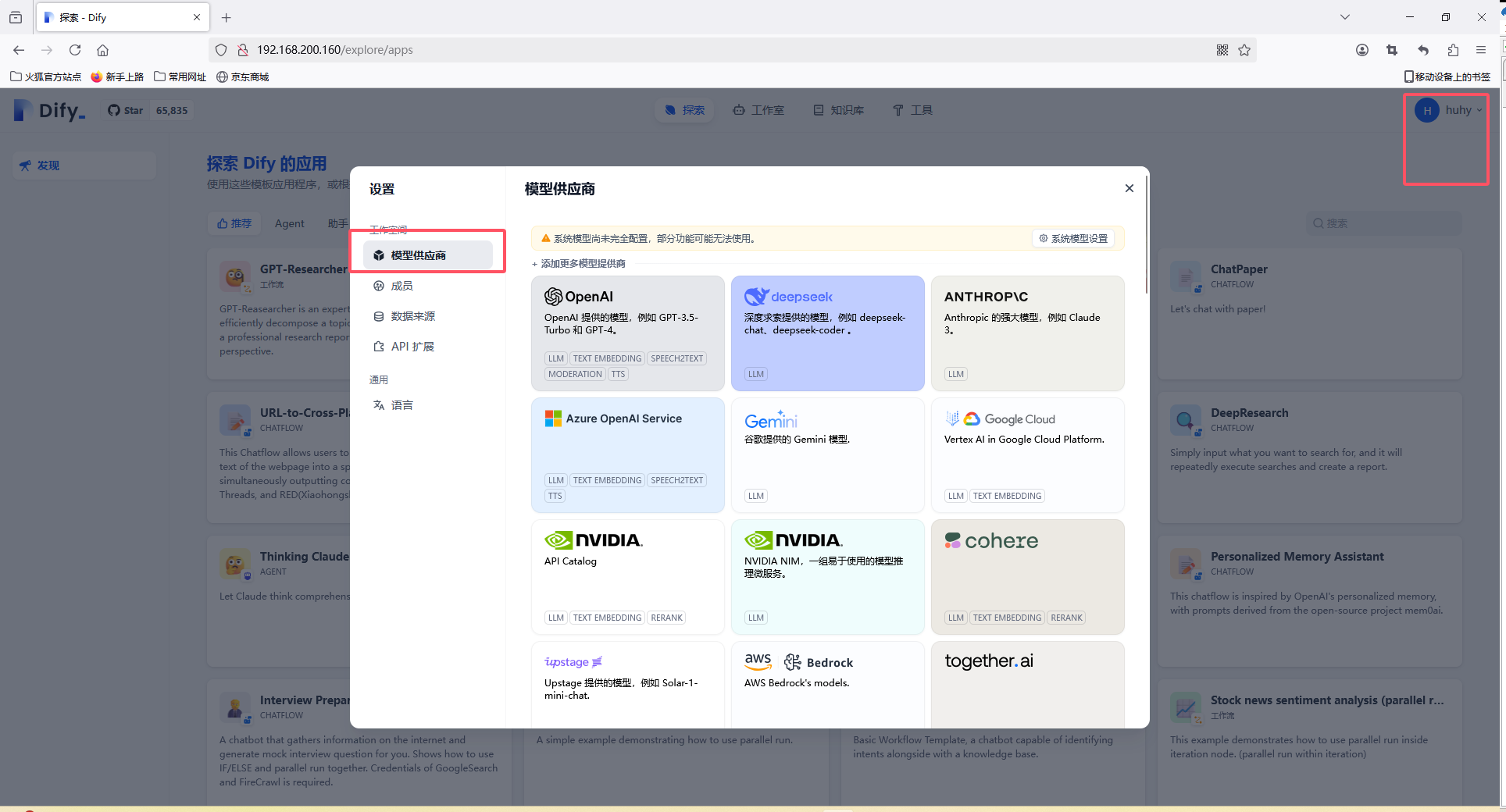
选择Ollama,添加大模型:只需要修改名称和地址即可,注意地址是本地还是远程
名称一定要对应不然会报错:An error occurred during credentials validation
PS C:\Users\huhy> ollama list NAME ID SIZE MODIFIED deepseek-r1:32b 38056bbcbb2d 19 GB 9 hours ago deepseek-r1:14b ea35dfe18182 9.0 GB 11 hours ago deepseek-r1:8b 28f8fd6cdc67 4.9 GB 11 hours ago deepseek-r1:7b 0a8c26691023 4.7 GB 11 hours ago deepseek-r1:1.5b a42b25d8c10a 1.1 GB 11 hours ago
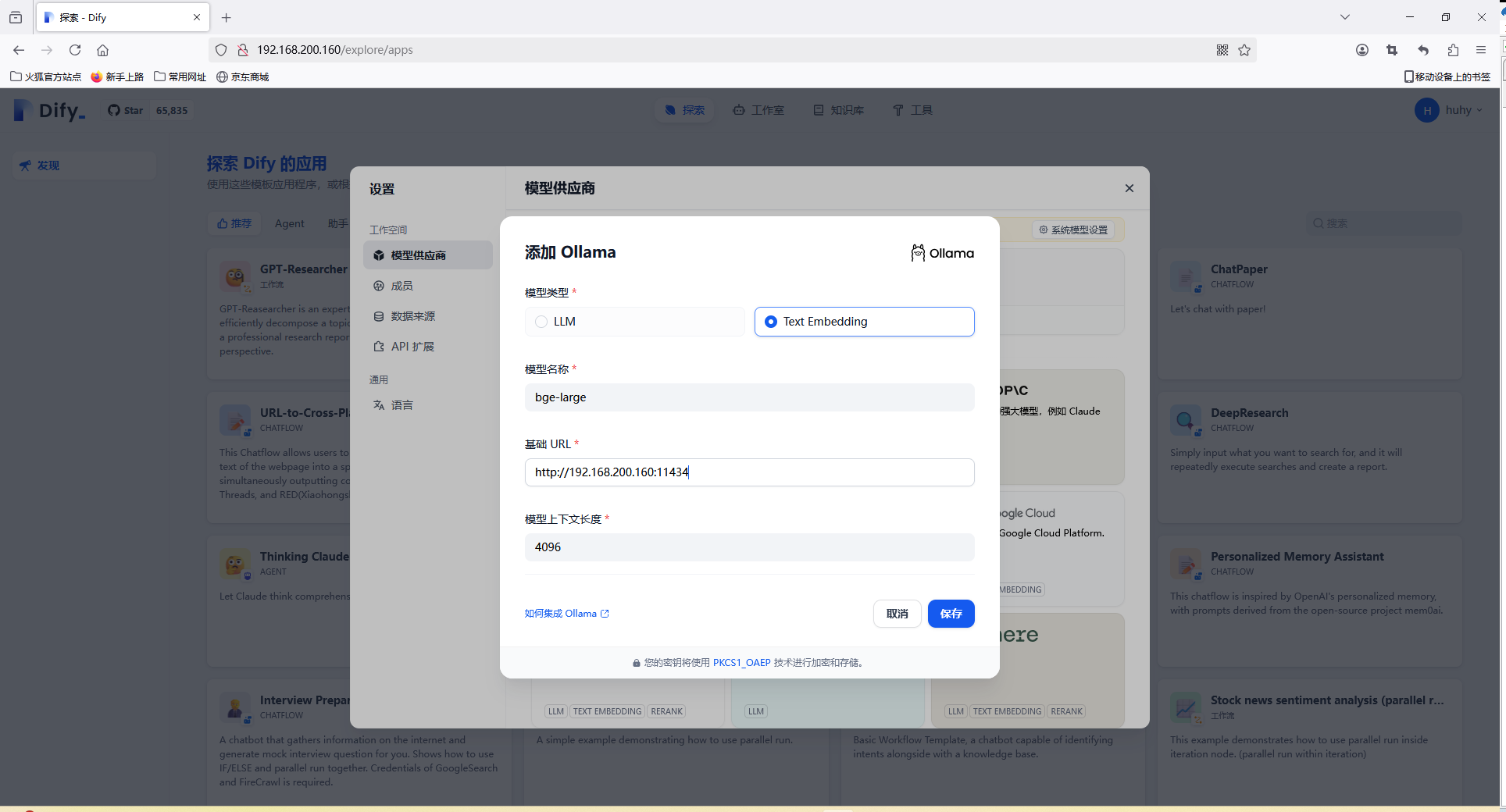
bge-large 是一个 Embedding(文本向量化)模型,全名是 BAAI General Embedding (BGE),由 BAAI(北京智源人工智能研究院) 开发,主要用于 语义搜索、文本检索、相似度计算、RAG(检索增强生成) 等任务
bge-large 主要应用场景:
分别测试不同参数的模型回答问题的准确性:文档中提到金奖的数量为参数队伍总数的10%,直接向AI提问(现在参加云计算竞赛的选手有65支,那金奖数量会有多少?)

要连接到另一台服务器上的 Ollama,请更改OLLAMA_BASE_URL为该服务器的 URL:
docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=https://example.com -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
官方文档
然后根据提示创建知识库
配置本地知识库
Docker安装RAGFlow
配置本地知识库
Docker安装Open-WebUi
Docker安装Dify
安装Ollama
实现本地部署DeepSeek-R1-14B模型")
的技术详解及简单示例演示")

