
前文:一直在研究大模型接口的流式对接,很好奇打字机效果如何实现,踩了很多坑,而网上能找的资料少之又少,既然没人讲,那就我来!
正文:不浪费时间,直接上代码。
总的思路有两种,一种真正意义上的流式数据返回,一种是模拟的打字机效果。
1. 流式数据返回
后端代码(基于springboot实现)
@PostMapping(value = "/streamModel", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux streamModel(@RequestBody String message) {
// 构造消息列表
List chatMessages = new ArrayList<>();
// 设置默认系统文本(简单理解是构建模型的人设)
chatMessages.add(new ChatMessage("system", "你的身份是一个专业的全能的专家,你的名字叫小林,请以恭敬的语气回答客户的问题!"));
chatMessages.add(new ChatMessage("user", message));
// 构造模型对象
ChatCompletionRequest request = new ChatCompletionRequest();
request.setModel("glm-4-flash");
request.setMessages(chatMessages);
request.setStream(true);
request.setInvokeMethod(Constants.invokeMethodSse);
ModelApiResponse modelApiResponse = clientV4.invokeModelApi(request);
AtomicReference content = new AtomicReference<>("");
// 遍历数据流,将每个元素中的content进行拼接,最终返回拼接后的content
return Flux.from(modelApiResponse.getFlowable()).map(
data -> {
content.set(content.get() + data.getChoices().get(0).getDelta().getContent());
return content.get();
}
);
}
代码讲解:在JAVA中,实现流式数据返回一般是使用SSE,那么JAVA是提供了Flux来实现SSE,即允许服务器向客户端推送数据的技术。属于单向通信技术。
在上述代码中,对接的是智谱AI的接口,具体的对接参数构成,请自行参考不同的大模型的接口说明文本,这里不一一讲述。成功访问到大模型获取回流的数据后,即到了这方代码这一步,算是获取到了大模型的数据流。
ModelApiResponse modelApiResponse = clientV4.invokeModelApi(request);
重点在后面部分,
return Flux.from(modelApiResponse.getFlowable()).map(
data -> {
content.set(content.get() + data.getChoices().get(0).getDelta().getContent());
return content.get();
}
);
通过Flux.from()将数据流中的数据进行批量的向前端接口返回,而该方法内,实际上是对大模型接口返回的数据的一个处理,处理成你希望给到前端返回的数据形式。这里,我将数据进行提取,将每次返回的文本数据与已发送的数据进行拼接,重新组成一个相对完整的数据。如果不处理,大模型接口默认的数据返回是这种形式,即部分字符形式:
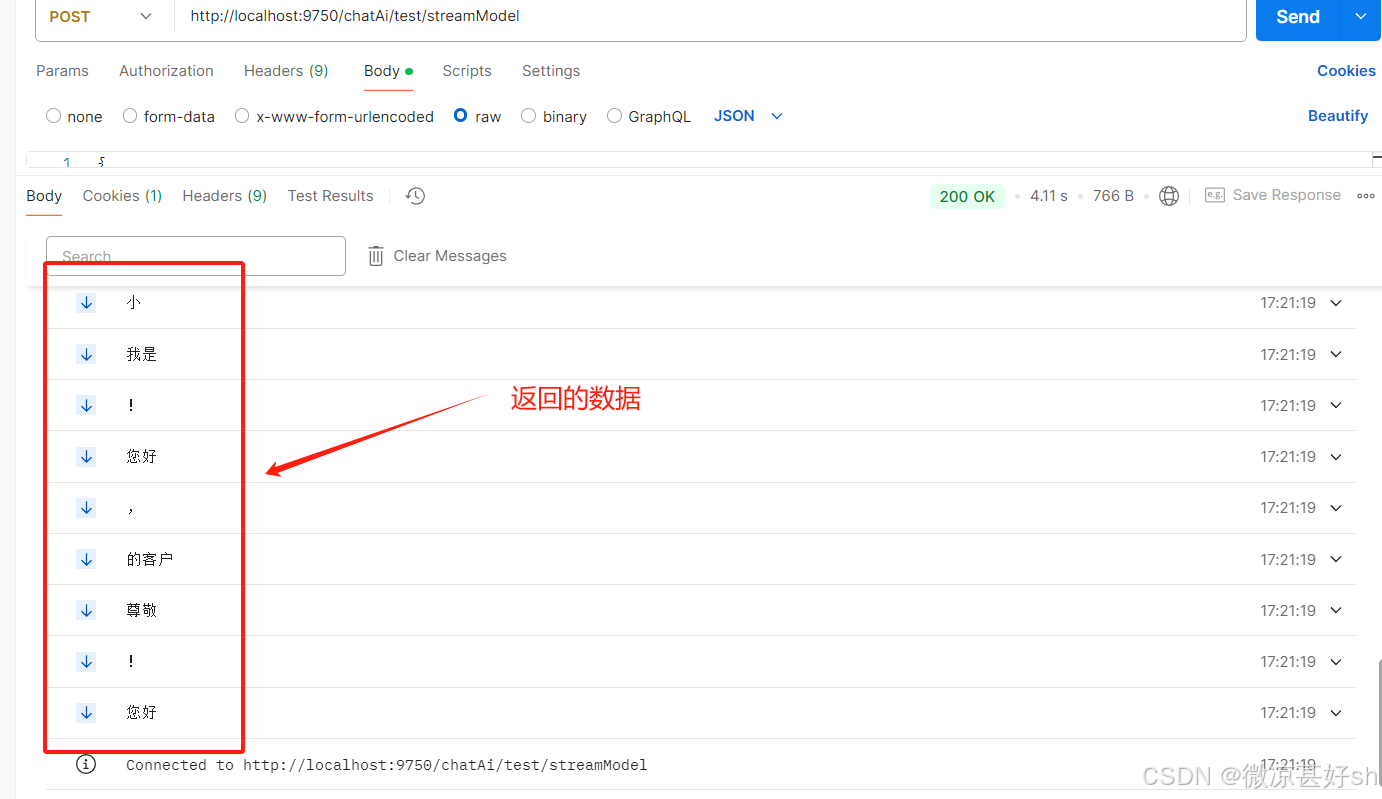
数据处理后,效果如下:
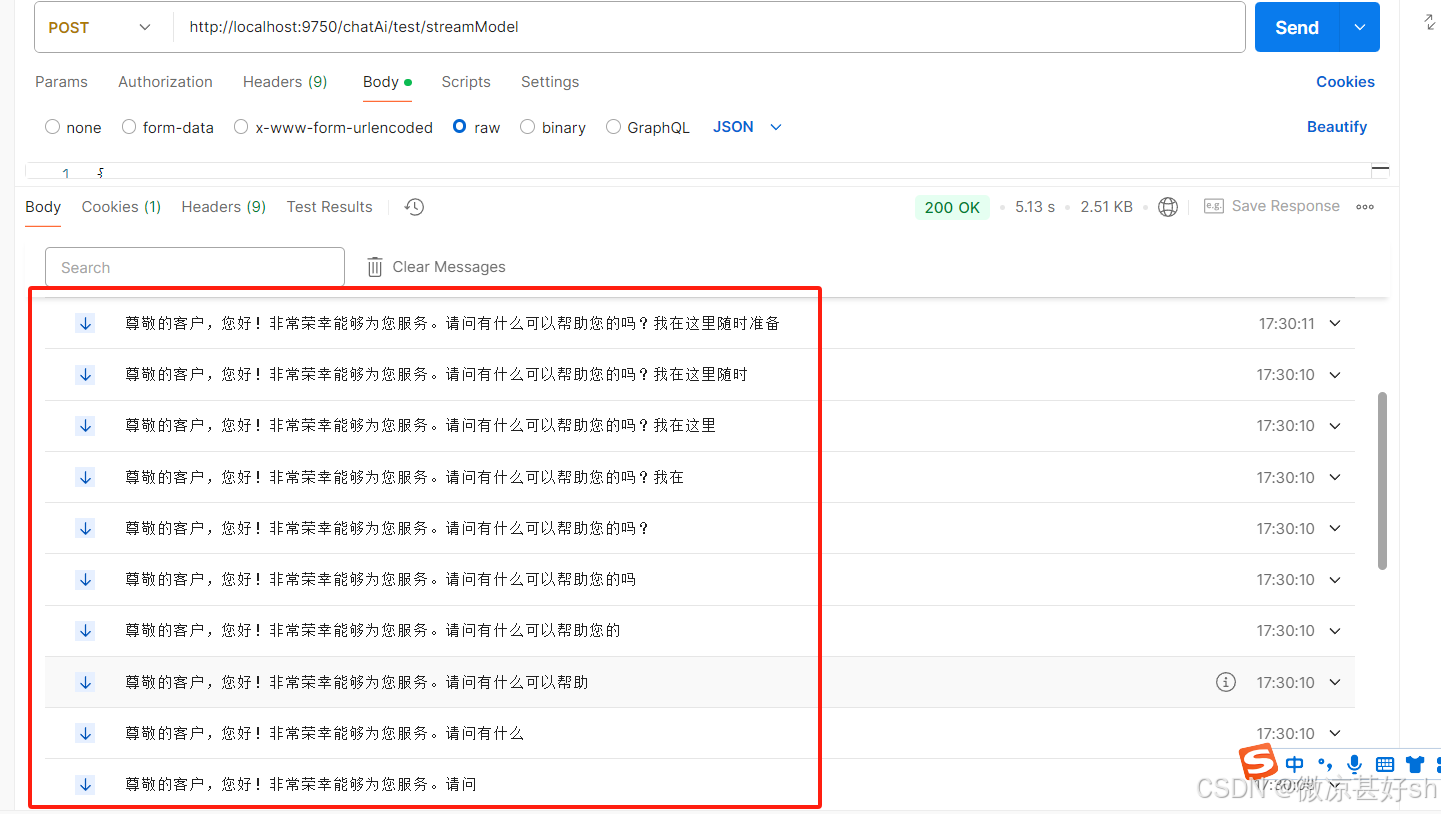
这种数据形式是大部分AI网站的主流数据返回形式,基本都是在后端进行处理再返回给前端,不会交由前端处理。到这,我们要稍微思考一下,为什么要这么做?
其实这算是个坑,前端一般我们会借助markdown插件,将数据进行渲染和显示。
尊敬的客户,您好!根据您的需求,以下是一个简单的Java程序,用于打印出“Hello, World!”。请您参考:
```java
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, World!");
}
}
```
只需将上述代码复制到Java开发环境中,编译并运行,即可看到“Hello, World!”的输出。如有其他问题或需求,请随时告知。
这是一段markdown文本,其中我们会看到代码的部分是会有代码的标记符号的,如```java 内容 ``` ;那么如果你后端直接将接口原数据一动不动返回,那么很可能在前端处理并显示时,会出现,代码粘连,即:“javapublicclassHelloWorld”这样的情况,亦或者 会由于格式的变化,导致前端插件忽略你的代码块,从而不显示。所以,记得避坑!
同时,还有一个地方需要留意,我们在使用流式的时候,后端接口一定需要加上:
produces = MediaType.TEXT_EVENT_STREAM_VALUE
它表示该方法将返回一个 Server-Sent Events (SSE) 流,不加这个,即使你用Flux去返回数据,最终还是一次性响应,实际上流式是不生效的,切记!
还有一个注意点,日常开发中我们会形成一个习惯,会封装各种各样的数据返回类,切记,在这里不能用,用了不报错,但拿不到数据,流式也不生效。
前端代码:
前端接收SSE数据,比较常用的有两种,第一种是使用fetch去请求接口获取数据,第二种是使用EventSource API去获取数据,下面结合代码来讲解一下:
首先是fetch,这是基于vue2的代码,重点是connectToServer方法,里面使用fetch去向后端发起一个post请求,拿到数据后对数据进行处理,包括数据的一个重新编码之类的,主要防止乱码,然后就是使用正则表达式去替换掉数据中的“data: ”字符,为什么要替换掉呢,当使用SSE进行响应数据时,他的固定格式一定是 data: 你的数据内容 ,所以需要去掉前面的前缀,最后我们将数据给到 typedText,在渲染到自己的markdown组件上就能显示了:
效果展示,可以看到内容以打字机的形式进行输出,而右边接口处能够看到接受数据的大小和时间都有变化,且没有别的接口在请求,始终都是这一个接口在工作:
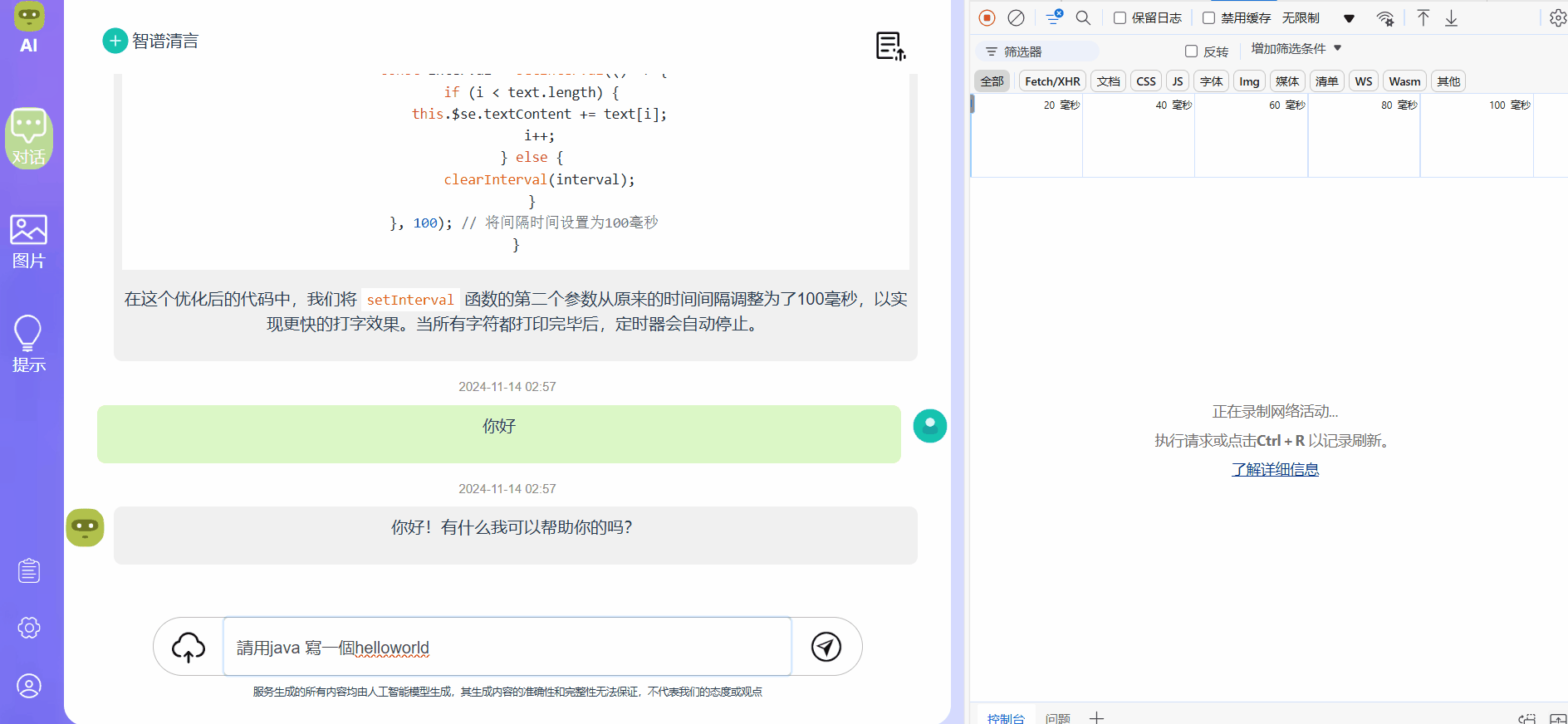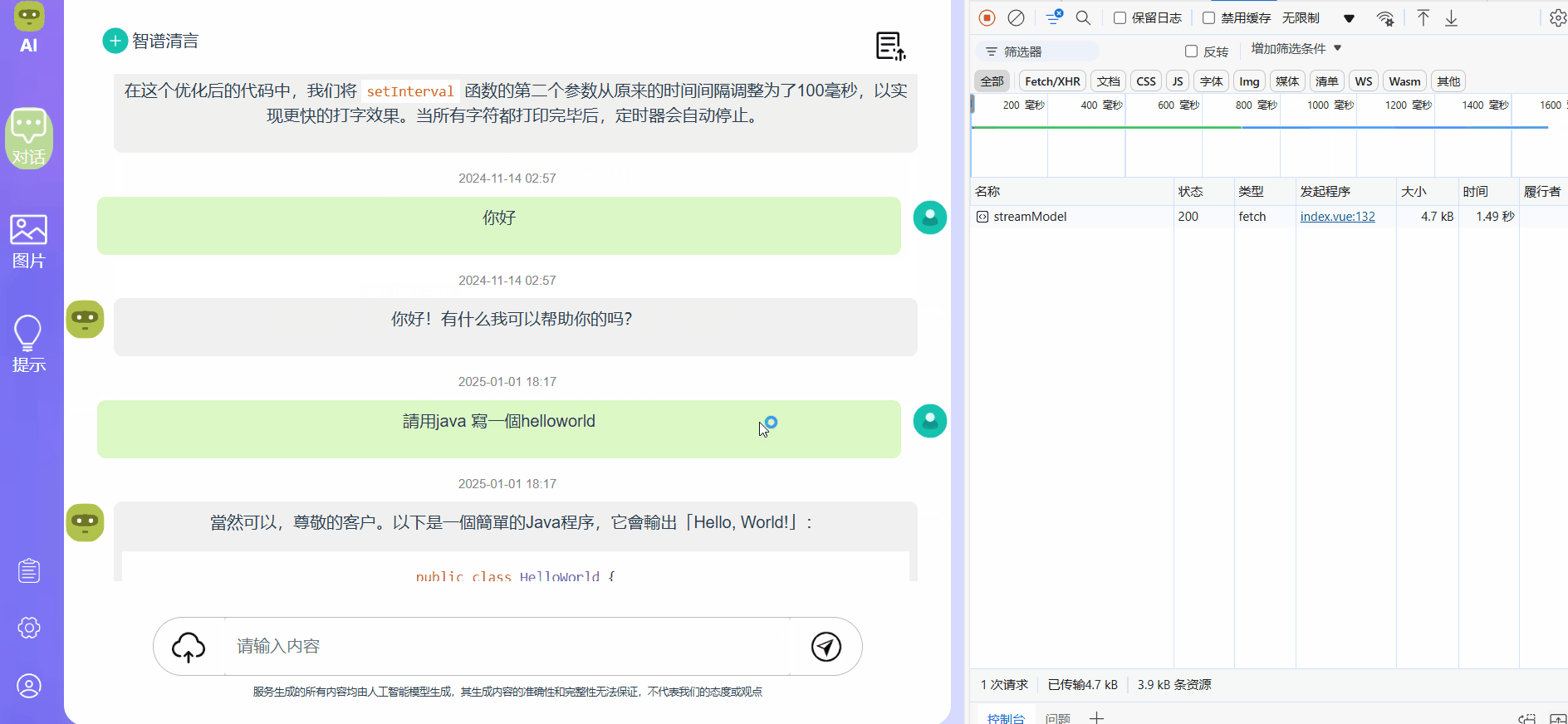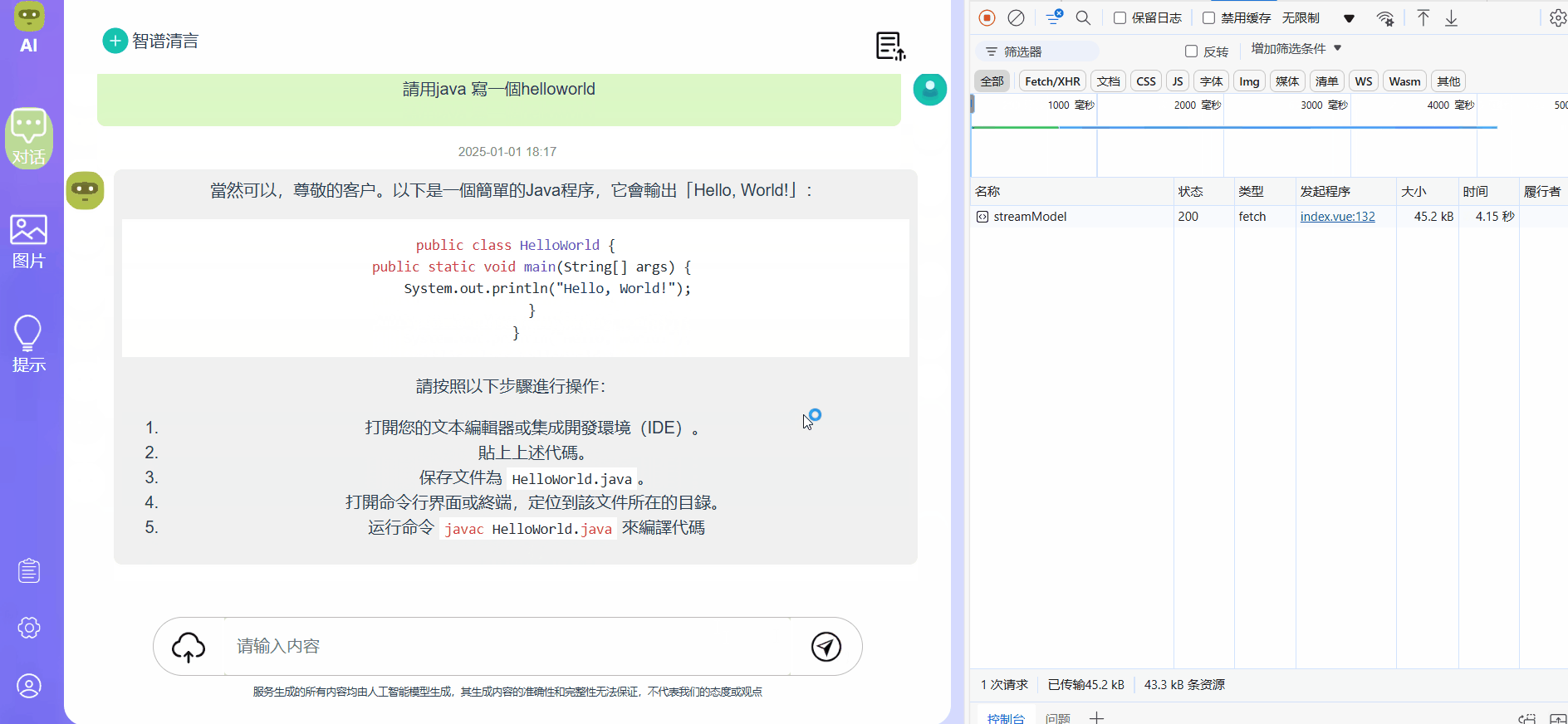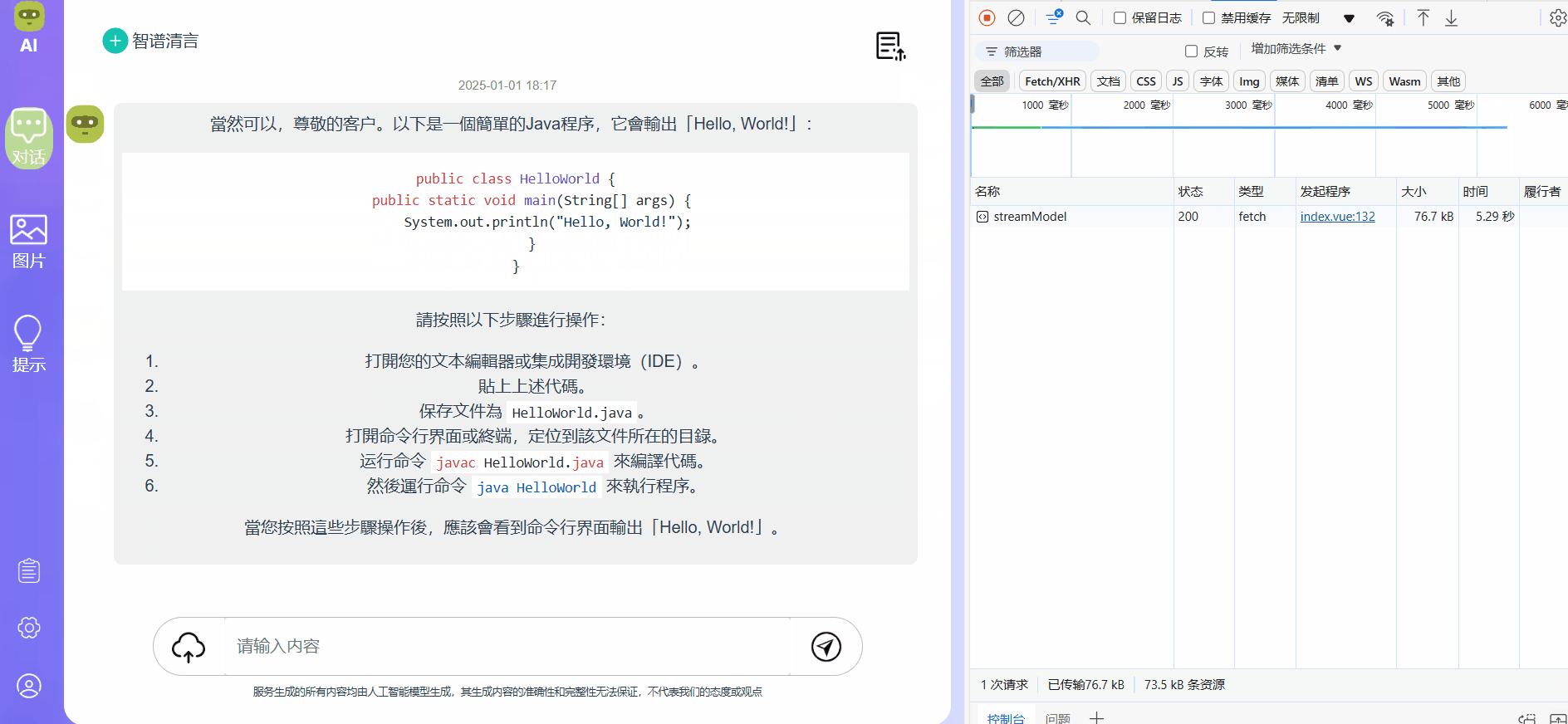
其次就是使用EventSource API去实现请求:
效果跟上述的fetch是一样的,这就不多说的。
差异性:从代码都能看出
1. EventSource API代码会相对简单,fetch会相对复杂一点
2. EventSource只能使用GET请求,fetch支持POST和GET,相对更安全
总结:一般AI网站用的都是fetch的形式,它优于EventSource API
2. 模拟打字机效果(不推荐,但难免某些场景无奈要用)
正品讲完了,我们来讲讲仿品,不感兴趣的同学可以跳过了哦。
思路:获取接口的一次性数据,在前端以模拟打字机的形式进行输出。需要注意的是,一次性获取接口数据,可能会存在问题过长,后端获取数据过慢而导致的接口超时,这需要你自行去设置前端访问后端接口的一个超时时间,以此来防止超时的问题。
缺点:接口超时报错问题,等待时间过长影响用户体验,无法实现ai回答时的一个停止回答操作
直接上代码(温馨提示:代码是因项目而定的,并不适用,需要实现这样的效果时请直接问AI,都会给你生成的,这个仅仅作为参考,作用不大,重要的只是思路):
// 打字机效果
export function typewriterEffect(index, text, vm) {
let i = 0;
const interval = setInterval(() => {
if (i < text.length) {
vm.$set(vm.messages[index], 'text', text.slice(0, i + 1));
i++;
} else {
clearInterval(interval);
}
}, 20); // 控制打字速度,20毫秒一个字符
}
这是一个写在js文件中的一个方法,便于复用,用的时候需要这样调用:
typewriterEffect(this.messages.length - 1, text, this); // this.messages.length - 1 在这 ,messages是一个数组,数组长度减1才是真正的索引下标 // text 是响应的data数据 // this 是当前的vue实例



 never called问题")